

I. Introduction
As artificial intelligence (AI) capabilities become more and more sophisticated, legal educators and practitioners may have to confront the possibility that in the foreseeable future, AI will be able to write the basic and foundational legal document, the one with which we train our students to first write out legal reasoning, the office memorandum. Even if AI’s ability to write out a full memo is still in the future,[1] at present AI can contribute fruitfully to the memo writing process. Our goal in this Article is to answer these questions: How far can and do AI capabilities go when it comes to legal writing? Can AI do the kind of sorting, analysis, and text generation required for solving legal problems and writing analytical legal documents? What AI skills will new lawyers need in the not-so-distant future in order to be prepared to enter legal practice?
First, however, here is a brief introduction to the field of AI and Law. AI is a subarea of computer science in which researchers develop computational models of behaviors that normally require human intelligence.[2] AI and Law, in particular, focuses on modeling legal reasoning behaviors.[3] Recent developments in AI and in legal text analytics have led to some new tools for legal research, many of which are now familiar to most lawyers and legal educators. Legal text analytics refers to techniques for automatically extracting information from archives of legal documents including case decisions and statutes.[4]
Legal text analytic tools employ machine learning, network diagrams of citations, and question answering. Machine learning (ML) refers to computer programs that use statistical means to induce or “learn” models from data with which they can classify a document as relevant to a claim in e-discovery or even predict an outcome for a new case.[5] Network diagrams graph the relations between objects and can assist in making legal information retrieval smarter. In a citation network, the connected objects may be legal cases or statutory provisions.[6] Question answering (QA) systems search large text collections to locate documents, short phrases, or sentences that directly answer a user’s question.[7] IBM’s Jeopardy-Game-winning Watson program is, perhaps, the most famous example of a QA system. The ROSS program,[8] based on Watson technology, answered legal questions.[9]
We already are seeing AI review contracts and other kinds of transactional “boilerplate” legal documents that vary little from transaction to transaction. Additionally, machine learning is on its way to dominating the discovery process.[10] And we already know that with a few clicks, a computer legal research program can quickly turn up virtually all the relevant law and secondary sources needed in a particular situation—provided the researcher frames the search well—working from vast amounts of data. New developments are inevitable, including AI’s capacity to generate office memoranda,[11] or something that can serve in its place.
Producing an office memorandum, however, is a complex process that involves multiple steps, some of which may already be AI-assisted and some of which may remain forever outside of AI’s range. In Part II, this Article briefly lays out the steps through which a typical legal writer/researcher must go to produce an office memorandum, those same steps to which most legal writing courses introduce students and through which students progress in producing a document. Then, in Part III, the Article briefly introduces some AI techniques for the legal domain and discusses which of these steps AI can currently perform, which steps it will be able to perform in the foreseeable future, and which steps will probably remain in human hands.
This Article lays out a typical office memorandum template that many legal writing teachers use to teach students the form and discusses the possibility of AI writing such a document. It also probes whether AI could write different but equally useful documents.
Finally, in Part IV the Article discusses the teaching challenges that this possibility will pose in the legal writing and analysis classroom. Even if AI may not perform all of the tasks, it will likely be able to participate in writing an office memorandum. If so, what should we be teaching our students? The mere mention of the possibility of AI writing an analytical legal document quickly leads to consternation among law students and legal educators who see AI as threatening an already diminishing job market. That threat indeed might materialize if we do not adapt our pedagogical approaches. Since an entry-level attorney might soon find themself working with AI to produce documents that can be more thorough, accurate, and certainly more quickly produced than those written solely by a human attorney, legal writing courses should prepare students for this kind of AI-lawyer collaboration.
This Article offers an assessment of the present status of AI and legal writing capabilities and also provides a glimpse into the future: what AI is poised to do in the near future and which attorney writing activities seem beyond the reach of AI. As we will see, AI currently can process a natural language description of a legal question or short scenario and return answers and relevant cases. Students still need to read the cases to select and frame legal questions, identify questionable elements, search for cases concerning those elements and analogize them to or distinguish them from the problem scenario, and ultimately, draft the memo. Having done so, however, they can submit the draft memo to an AI program for suggestions of additional issues or cases to cite. For a limited variety of legal memoranda, AI can draft a memo automatically. For certain types of cases, AI can predict an outcome given a textual description of a case’s facts, but it cannot yet provide an explanation or justification. The newest AI can draft a paragraph or two of apparent legal analysis in a sophisticated kind of cutting-and-pasting based on texts in its enormous collection but with no guarantee of legal accuracy.
II. How One Gets from a Legal Problem to a Document: A Traditional Approach
In a simple scenario, a client walks in the door and presents an attorney with a problem: someone breached a contract with me; the insurance company won’t pay me; I was injured at the riding stable. The client seeks the attorney’s help in finding a legal solution to their problem and wants to know the chances of success. To analyze the client’s problem, the attorney writes (or assigns someone else to write) an office memorandum. At a granular level, here are ten steps that must be undertaken, from the client walking in the door to the production of the office memorandum.[12] Each step below is accompanied by a simple extended hypothetical to illustrate a concrete example of what occurs in the step.
In Part III, we discuss whether and how current AI capabilities can assist in the process. New software applications for legal practice (“legal apps”) help to address the ten steps but not necessarily in the same order as the manual process. In Part IV, we reorder the steps to address pedagogical goals given AI’s capabilities.
A. Ten Step Process for (Manually) Preparing a Legal Memo
Step 1: Interviewing the client and discerning the relevant facts
Before analyzing the law, the attorney must interview the client and discern what facts in the client’s narrative are legally relevant.[13] The attorney must listen empathetically to the client, who could be distressed, ask meaningful questions to pull out potentially important or clarifying facts, and sort through the story that the client tells to determine the legally relevant facts.
Figure 1 illustrates a hypothetical fact situation that, let us assume, captures the client’s story as told to the attorney.
Step 2: Determining the broad legal question and searching for the governing macro-law
Next, the attorney must translate the client’s question (sometimes something as broad as “am I in trouble?”) into a general legal question and begin the research process. Experienced attorneys can usually easily recognize the broad area of law and come up with a general legal question (Is my client liable? Did she break a law? Is he bound by the contract?). Then, before beginning research, the attorney must filter for jurisdiction and area of law, a process that is likely already using technology. Is the legal problem state or federal? If state, which states? Using jurisdictions and keywords in the client’s narrative—for example, landlord/tenant, dog bite, etc.—the attorney can find the governing macro-law.
To continue the analysis of the hypothetical in Figure 1, JC’s problem is likely governed by Illinois state law. The initial search would be for statutes in Illinois that regulate dog bite cases. The researcher would have to think through all the keywords by which the statute might be found: for example, animal control, injury from animals, dog bite, etc. Nearly any researcher would conduct all of the research online, using one or more of the computer-assisted legal research platforms, such as Lexis or Westlaw. The initial search of Illinois statutes and “dog bite” in JC’s case turns up 510 Illinois Compiled Statutes 5/16 and 510 Illinois Compiled Statutes 5/2.16 (Figures 2 and 3).
Step 3: Pulling out the required elements of the macro rule
Once a governing statute or case rule is found, the attorney must break the rule down into its component parts. What must be shown for the rule to apply? What exceptions exist? How are the rule’s terms defined? The statutes relevant to analyzing the hypothetical in Figure 1, and the statutes in Figures 2 and 3, can be broken down into elements as shown in the left column of Table 1.
Step 4: Applying the client’s facts to the elements
Next, the attorney must apply the client’s facts to each of the law’s required elements, definitions, exceptions, etc. Only then can the attorney see if that law indeed applies and speculate as to the outcome in the client’s case. The attorney must also perceive what parts of the law are ambiguous in the client’s scenario and will require further research. The right column of Table 1 shows the initial results of applying the client’s facts to the elements of 510 Illinois Compiled Statutes 5/16 and 5/2.16.
Step 5: Identifying any questionable elements
Once the facts are applied to the rule’s elements, the attorney can discern what needs further research. For example, elements viii through xii in Table 1 are questionable: it could be ambiguous as to what harboring a dog means, what having a dog in one’s care means, or what acting as a custodian means. It is also possible that JC would not be considered an owner under the statute because she did not knowingly permit the dog to be at her house, although she did knowingly permit it to remain.
Step 6: Searching case law for clarity on questionable elements and sorting through cases for relevance and applicability to the client’s problem
Next, the attorney conducts a search of cases within the jurisdiction in which courts have further defined or at least provided guidelines for the questionable elements. If no cases within the jurisdiction appear to deal with a questionable element, the attorney might look to persuasive authority from other jurisdictions.
With respect to the questionable items in Table 1 (elements viii through xii), the attorney would conduct a search through Illinois case law to see how Illinois courts define “owner” under the statute, focusing particularly on whether it matters if a person knowingly accepts responsibility for the animal. A Westlaw search (on May 23, 2022) of “‘510 ILCS 5/1’ AND owner” turns up forty-six cases and blurbs saying anyone who harbors or cares for a dog and who places himself in the position of an owner taking on owner-like responsibilities is liable even if not the legal owner. Not all forty-six are relevant, and the attorney would have to select the “best” cases. The cases would need to be filtered for similar facts—non-owner caring for dog that injures someone. Other factors, such as level of the reviewing court and date, also go to relevance. The attorney must at least skim through all forty-six of the cases to see if the facts are analogous and to decide if the court’s analysis would apply to JC’s situation in order to narrow the search to the five[14] relevant (“best”) cases.
Step 7: Synthesizing a rule from the relevant cases
This step entails several complex sub-steps: organizing the cases as to outcome; carefully analyzing the reasoning in each case to determine why the court held as it did, that is determining what principles or rules the courts used in reaching their decisions, some of which may not be explicitly stated in the cases; and then synthesizing the various rules from the cases to speculate as to what rule a court in the jurisdiction would apply in the client’s case. In some instances, binding precedent may not be on point or may be absent. In that case, an attorney/researcher would look for similar cases in other jurisdictions in order to think through a likely outcome.
The relevant cases would be organized by whether the court found that the animal caretaker was the owner and why. For example, the top row of Table 2 illustrates one positive and one negative case.
The line between yes and no, that is between whether a caretaker is an “owner” and thus liable or not, seems to be the following: whether the caretaker voluntarily assumed a significant level of care and control of an animal, similar to the level of care and control a legal owner assumes, such as feeding, providing water, and letting outside. Smaller actions, like occasionally providing food or water, if not required for the care of the animal, do not rise to the level of care required for liability. This statement would be the synthesized rule.
Step 8: Analogizing and distinguishing searched cases
Next, the searched cases would be analogized to or distinguished from the current case by comparing the client’s facts to the facts in the cases. The bottom row of Table 2 illustrates distinguishing the positive case and analogizing the negative one.
Step 9: Predicting the outcome
An attorney would then assess the results from the steps listed above and speculate as to what would happen should a court consider the client’s case. A good attorney, however, would do more than compare the cases and outcomes. He or she would research and think through the purpose of the law in question. What outcome were the lawmakers seeking and how would a likely outcome in the client’s case fit into the law’s purpose?
In the extended example, an attorney would think through how a court would apply the synthesized rule in Step 7: A person is an owner under the statute when that person voluntarily assumes a significant level of care and control of an animal, similar to the level of care a legal owner assumes, such as feeding, providing water, and letting outside. It seems a likely outcome that JC would not be considered an owner when the attack occurred because her friend dropped off the dog without JC’s knowledge and JC had not voluntarily assumed owner-like responsibilities for the dog. The attorney would also have to consider and weigh possible counter-arguments—what actions did JC take, like allowing the dog to remain, albeit reluctantly, and giving the dog water and a treat—that could constitute owner-like care and control. Finally, a thorough attorney would take into account the statute’s purpose—to compel people who have responsibility for an animal, even if not legal owners, to control the animal so that the animal does not injure someone.
Step 10: Writing the office memorandum
All of the steps listed above would have to be translated into some kind of document that could be used by another attorney to advise the client. Typically, this document is an office memorandum. See Appendix A for a legal memo, drafted by a human attorney, that addresses the various points made above.
III. How AI Would Help to Prepare a Legal Memo
Having seen the steps that law students would be taught in preparing a legal memo, let’s now examine how AI could be involved in each steps. For purposes of exposition, we will take the steps in the order presented above and examine the extent to which AI approaches can perform them. As we will see, some steps are currently beyond AI capabilities, and some will always be so, but others are matters of research in AI and Law and may be possible in the foreseeable future.
Sometimes the AI approaches address the steps or parts of steps in a different order; sometimes they skip ahead or combine parts of different steps. In Part IV, we will summarize how law students currently could apply AI tools to address the memo writing task and how students might be taught the still relevant lessons of the traditional approach. As illustrated there, the steps may be reordered depending on which parts are automated and which are still manual.
AI approach to Step 1: Interviewing client, discerning relevant facts
A legal app probably could not engage in a freeform aural conversation with JC to obtain the facts (Traditional Step 1). Along these lines, researchers in AI have built user interfaces or chatbots that are able to ask clients for details about their facts.[15] The medium might be audio, but more likely it would combine menus and short text fill-ins in response to written questions. A program probably cannot yet interpret a client’s audio rendition of their problem scenario due to its length and the tendency of humans to speak in sentence fragments and sometimes ungrammatically or emotionally.[16]
Although empathy should be part of the lawyering process, AI systems listening empathetically may be unlikely for some time. Thus far, AI systems are able to detect positive and negative sentiments in text and in the kinds of voice communications involved in customer service applications. They are still a long way from distinguishing emotions such as anxiety or distress, drawing indirect inferences, or reacting to emotions by responding empathetically.[17]
A legal expert system is a kind of computer application that can “provide advice specific to a given scenario” based on a human “experts’ knowledge captured in a sophisticated and often complex logic or rule base.”[18] If one were available, it would drive the questioning in Traditional Step 1 using a set of human-authored rules defining the relevant claims and their requirements.[19]
Such an expert systems app would be restricted to a small list of particular types of legal claims for which humans had created a list of rules. Assuming that someone has created an app for dogbites under Illinois law, Figure 4 shows a sample set of questions driven by rules derived from the language of the statute, 510 Illinois Compiled Statutes 5/16 and 5/2.16. Given the limitations of current natural language processing techniques, the human expert would have to produce these rules manually because it is not yet possible for a program to analyze the texts of such statutes and generate rules automatically.[20]
The expert systems app would ask questions in order to narrow down which of the claims is relevant. The order of questions, however, might be flexibly determined by the order in which the client provides inputs. Where necessary, the questions would be supplemented with additional, more factually specific questions and menus of possible responses. While users might fill in blanks with names of the victim, dog owner, and so on, the ability of AI programs to interpret free text is still limited by the need for training machine learning with many instances of possible answers.[21]
A system would need a set of expert rules covering an area of law in order to focus on the right questions to ask about facts. Probably no AI program could ask questions of the type appropriate for Traditional Steps 1 and 2 across the broad range of problems with which a practicing attorney regularly deals. Conceivably, however, a system could be an expert on interviewing more generally about types of injuries to various economic, physical, and emotional interests and their causes for purposes of identifying the relevant areas of law and claims or computing damages.[22] For example, it might ask:
-
Were you the victim of an injury? (Yes / No)
-
What kind of injury did you experience? (Medical Injury / Property Injury / Pain and Suffering / Emotional Distress / Lost Wages / Other)
-
Did someone or something cause the injury? (Yes / No)
-
What kind of person or entity caused the injury? (Person / Corporation / Government Officer / Other)
-
How did the person or entity cause the injury? (Carelessness / Intentional Act / Defective Product / Other)[23]
Alternatively, a human would need to ask such questions, and having identified potentially relevant claims, could direct the client to an appropriate expert system with expertise in those kinds of claims (if one is available to the attorney) which could then ask claim-related questions to generate a set of facts like the hypothetical of Figure 1.
Thus, although an AI system cannot interview empathetically or generate relevant questions from a statute, with significant human intervention in creating lists of questions from statutes, AI systems could improve efficiency in client interviews.[24]
AI approach to Step 2: Determining legal question, searching for governing law
Similar considerations arise with respect to determining the applicable jurisdiction and governing law. Presumably, an expert system would ask questions to establish facts on which to determine what subject matter jurisdiction would apply (Traditional Step 2). This would, again, require a set of human-authored rules dealing with at least some of the ins and outs of tort jurisdiction keyed to the type of claim, such as where the injury occurred and where the action that caused the injury occurred.[25]
A key component of Traditional Step 2 is framing the general legal question with which to begin the research process. In the hypothetical, the human searches for statutes governing dogbite cases by submitting keywords such as animal control, injury from animals, and dog bite to Lexis or Westlaw, having selected a library including Illinois statutes.
With AI and natural language processing, framing the general legal question is not entirely necessary to obtain retrieval results. A more direct route is simply to submit the text of Traditional Step 1’s hypothetical (Figure 1) directly to a program such as Westlaw Edge, which supports analyzing natural language descriptions of problems.[26] If we submit the text in Figure 1 and specify the Illinois state library, a Westlaw Edge search (on May 23, 2022) retrieved sixty-eight cases, of which the top-ranked case is Goennenwein by Goennenwein v. Rasof, 695 N.E.2d 541 (1998). This case deals with a “Minor guest who was bitten by property owner’s son’s dog on owner’s premises brought personal injury action against owner.” All of the top-ten cases appeared to be relevant. In addition, selecting “Statutes & Court Rules” leads to the Illinois statute, 510 Illinois Compiled Statutes 5/16 Animal attacks or injuries and 510 Illinois Compiled Statutes 5/2.16 Owner.
Casetext is another program that can process natural language text.[27] It invites users to upload a brief to find relevant cases with CARA A.I. (which we will try later on), but let’s see what Casetext does when we submit into the search box the text of the hypothetical in Figure 1. On specifying Illinois as the jurisdiction and cutting and pasting the hypothetical into the search box (on May 23, 2022), Casetext retrieved twenty-four cases. Based on the blurbs generated by Casetext, ten of the cases dealt with dog bites but only one blurb flagged the issue of ownership of the dog. On searching within the results for the relevant statutes, three cases referred to the 510 Illinois Compiled Statutes 5/2.16 definition of owner; one referred to 70/2.06 which appears to be a shorter version under Act 70, Humane Care for Animals Act.[28]
While these AI-employing legal information retrieval tools can process natural language descriptions of problems as inputs, one still must read the program’s outputs of cases and statutes to see how they frame the legal question and bear upon it (as is also required for Traditional Steps 3 through 9).
If an attorney does frame a legal question explicitly, however, another AI approach is to submit it to a legal question answering (QA) system. An attorney inputs a question, and the program searches a database of case texts to identify sentences or short texts that appear to directly answer the question.[29] Until its recent shutdown due to a copyright dispute with Thomson Reuters,[30] the ROSS program was the best example of a commercial legal QA system.[31]
As noted in Part I of this Article, ROSS was based on IBM Watson.[32] An attorney could input a question in plain English, and ROSS answered with short passages drawn from cases.[33] For example, prior to ROSS’s closure, we submitted the query, “Is someone who is caring for a friend’s dog liable if the dog bites another person?” ROSS output numerous cases on liability for dog bites.[34] Machine learning (ML) was a key component of legal question answering in ROSS.[35] An ML model learned how to assess the probability that ROSS understood the user’s question, that it is a question it “knew” how to answer, and that a short text extracted from a case, in fact, answered the query.[36] Impressively, six of the top-ten ranked cases dealt with the specific issue of whether someone other than the dog’s owner could be liable and elaborated some conditions relevant to the issue.
Prefacing the first question with "In Illinois, . . . " led ROSS to return cases from that state, four of the top ten of which appeared to discuss the liability of persons other than the dog’s owner. Switching to the Illinois database and specifying Statutes & Regulations, ROSS lists 510 Illinois Compiled Statutes 5: Animal Control Act at rank five, although one must then explore on their own to find the most relevant sub-provisions. Interestingly, submitting a question differently phrased from the first query but with a similar meaning, “If a dog injures a guest while at the premises of a property owner, is the property owner liable for the injury even when the dog belongs to someone else?” yields only one obviously relevant case in the top ten. When one submits the whole text of the hypothetical, ROSS was unable to process it.
While ROSS-like tools provide a quick start to the research, the human user must still select the best cases from the ones that a tool returns on the basis of the extracted short texts and read them to determine the extent to which they answer the user’s question sufficiently to be incorporated in the memorandum. Similarly, if one submits the question “In Illinois, if a dog bites someone, is the caretaker who is not the owner liable?” to Google, it returns the answer in under a second. A lawyer could not rely on that source but would have to circle back and look at the actual statute. Nevertheless, it also provides a quick start.
Thus, AI tools can help students begin to frame a legal question and search for governing law, but the burden remains on the students to evaluate and adapt their results.
AI approach to Step 3: Pulling out macro rule’s elements
It may seem a straightforward task for law students to break down statutory provisions like 510 Illinois Compiled Statutes 5/16 into a list of elements like that in Figure 4, but it is not something that comes naturally. Students need to be taught why the task is useful and how to perform it. They also need some practice in doing so, but they pick up the skill fairly quickly.
Computers would not pick up the skill so easily, if at all. In general, AI programs cannot yet generate a logical rule summarizing a list of elements and exceptions directly from the text of statutory or regulatory provisions.[37] While a natural language parser like the Stanford Parser[38] has no apparent difficulty in parsing, that is, working out the grammatical structure of, the sentence-long texts of 510 Illinois Compiled Statutes 5/16 or 5/2.16 (Figure 2 and Figure 3), it cannot recognize which parts correspond to elements of the legal rule. Other statutory provisions are much longer, more complex, and more challenging to parse. Statute sentences often contain long lists of items or nested subordinate clauses, making parsing much more difficult. Even automatically segmenting the provision into sentences presents technical challenges.[39]
Once the statutory provision is parsed and segmented, other problems present themselves. One needs to recognize the discourse structure such as defining a term or stating a regulatory rule. If the latter, does the rule impose an obligation or prohibition, or does it provide a permission? Knowledgeable humans recognize these distinctions fairly easily; computer programs must be trained to do so.[40]
The statutory texts pose more difficult questions of semantic interpretation than most texts. For instance, statutory section 5/16 refers to “owner,” a term that has an ordinary meaning, but this is not an ordinary usage of a commonsense term. In fact, it is an indirect and implicit reference to the technical legal term “owner” as defined in statutory section 5/2.16. An astute legal professional would know enough to check which terms such as “animal,” “dog,” “owner,” or “person” are defined in the statute. They all are. The professional would likely note that according to 510 Illinois Compiled Statutes 5/2:
Sec. 2. As used in this Act, unless the context otherwise requires, the terms specified in the Sections following this Section and preceding Section 3 have the meanings ascribed to them in those Sections.
The professional would also note that section 5/2.16 follows section 5/2, which specifies and defines a term (i.e., “owner”), and precedes section 5/16. Thus, the professional would tentatively conclude that “owner” in section 5/16 has the meaning specified in section 5/2.16. Of course, they are left to wonder when “the context otherwise requires” a different meaning. This kind of statutory reasoning about what “owner” means is simply beyond the capacity of current AI systems.
A longtime goal of AI and Law researchers has been to build programs that could automatically summarize the elements specified in a statute and generate logical rules that succinctly capture the statute’s requirements.[41] The researchers try to enable programs to recognize patterns in legislative language that specify requirements.[42] Some work focuses on processing statutory provisions, which, like the Illinois dog bite statutes, comprise multiple sentences, such as a provision from the National Pension Law addressing suspension of pension benefits.[43] Progress has been made in limited domains like building regulations, but the general problem remains unsolved.[44]
An additional complexity is that statutory provisions can be subject to a kind of logical ambiguity due to the fact that, unlike logicians or mathematicians, legislators do not use parentheses to specify the scopes of logical connectors such as “if,” “and,” “or,” and “unless.” [45] They also make extensive use of cross-referencing, either explicitly or implicitly as with the “owner” example above. As a result of this syntactic ambiguity, even fairly simple statutes may exhibit multiple logical interpretations, which litigators are left to discover and exploit as the occasion demands and which create thus far unsolvable problems for AI systems.[46]
Consequently, the system designers of AI legal apps need to employ humans to extract the lists of elements specified by statutes and their logical connections and manually fashion them into rules that computer programs can employ. The rules that power legal expert systems or computational models of legal argument have largely come from human interpretation of the legal texts.[47]
Once lists of elements have been extracted, an AI legal app can suggest them to users as appropriate. For example, Lexis Answers, a relatively recent question answering service that law students may encounter when using Lexis+, suggests claim elements to a user based on the user’s partial input.[48] For instance, if a user types in “breach of contract,” it will suggest questions like “What are the elements of breach of contract?” and “What is the definition of breach of contract?,” among others. Upon selecting the question, “What are the elements of breach of contract?,” it lists the elements and provides links to three cases with such listings. Lexis Answers, however, cannot deal with all types of claims.[49] Upon inputting to Lexis+ the query, “What are the elements of a claim for dogbite?,” Lexis Answers was not activated. Thus, it seems that automatically extracting lists of elements may still be difficult even from cases containing such lists.
AI approach to Step 4: Applying client’s facts to the elements
In general, current AI systems would not understand the description of the hypothetical in Figure 1 well enough to determine which elements in Table 1 are satisfied. This would require more of an ability to understand what a sentence means, that is, what the sentence entails, than AI research has achieved, but not for lack of trying.
There has been a great deal of research in natural language inference and textual entailment. “Natural language inference is the task of determining whether a ‘hypothesis’ is true (entailment), false (contradiction), or undetermined (neutral) given a ‘premise.’”[50] Table 3 illustrates the problem in the context of the dogbite hypothetical.
Each row in the Premise column contains one or two sentences, that is, the premise. The Hypothesis column contains assertions that may or may not be entailed by the corresponding premise. The Relation column specifies whether the hypothesis is entailed by the premise, contradicts the premise, or is neutral with respect to the premise. Items 1, 2, and 3 are straight-forward examples of common sense inferences about the hypotheses given the premise. Modeling this kind of natural language inference has been the focus of AI research.[51]
In item 4, the premise is expanded to two sentences: the factual sentence about JC plus a clause excerpted from the definition of owner in 510 Illinois Compiled Statutes 5/2.16. Similarly, each of items 5 through 7 adds an additional clause from that statutory definition. The hypotheses in each of these four items specifies the dog’s legal owner, by which we intend to indicate that the meaning of “owner” is not the common sense meaning but the technical legal meaning.
These fairly simple modifications take the phenomenon well beyond the current AI research on natural language inference for several reasons. First, the premise involves two sentences, and the second of those involves multiple “OR” clauses. Second, the hypotheses specify the use of a technical legal term, “legal owner,” which definition is specified in the premise. Third, drawing inferences about the term presupposes knowledge of the distinction between common sense terminology/conclusions and legal terminology/conclusions. Let us ignore a fourth complexity— the subtle ambiguity in the meaning of “legal owner.” It may mean “owner as defined by law” but it may also mean “rightful owner.”
The task is similar to taking a bar examination in that one must know the elements of a claim or the requirements of a statutory provision and determine if they are satisfied or not given the facts of the problem. AI and Law researchers developed a system to answer true/false questions from a Japanese bar examination based on statutory texts.[52] Their approach involves matching the question to textually similar provisions of the civil law. In an entailment step, it predicts if it follows logically from the facts in the question that the elements of the provision are satisfied.[53] The hypothetical of Figure 1, however, appears to be longer and more complex and to involve considerably more common sense knowledge than the true/false exam questions dealt with in that work.
We have been speaking of AI research on understanding natural language text. A more traditional AI approach would involve expert systems. If an expert system were provided with rules from a human expert concerning the elements of legal claims for dogbite and the related kinds of facts, it could ask the client or the attorney about the facts from which the system could infer which elements were satisfied. Here again, the expert system would be limited to those sorts of claims for which someone had created sets of rules. As mentioned, there is still no way for an AI system to automatically infer such rules from the text of statute.
AI approach to Step 5: Identifying any questionable elements
So far, our account of determining which statutory elements are satisfied has omitted the task of determining which of the elements involves terms that are vague or ambiguous. An AI legal app would need to know if the term is vague or ambiguous in order to decide whether the term’s application to the dog bite hypothetical is debatable and subject to argument. Consider, for example, the italicized terms in elements ii and viii through xii in the left column of Table 1: without provocation, having a right of property in an animal, keeps or harbors, has it in his care, acts as its custodian, and knowingly permits. They are all debatable terms given the particular facts of the dogbite hypothetical. Other facts might make other terms debatable. Even “person” may be debatable in an age of robotic dogwalkers (or “dog” in an age of robotic pets).
Every law student taking an issue-spotting exam needs to determine which legal questions presented in the fact situation are “hard” and which are “easy” to answer, that is, which require considering arguments pro and con and which are not reasonably debatable given the facts. For quite some time, researchers in AI and Law have focused on how to identify the terms in a legal rule whose applicability in a given fact situation is arguable. As early as 1987, a computer program could distinguish “hard” and “easy” questions concerning offer and acceptance in contracts exams but only in manually-prepared representations of case facts.[54]
Today, it is feasible to process the the kinds of textual descriptions of facts that law students must analyze, but text processing is not sufficient. In general, AI has not computationally modeled the ability of lawyers to understand and creatively exploit opportunities for argument presented by specific facts based on the meanings of the statutory terms and particular facts or purposes underlying the regulations.[55] Just as AI and Law has not focused on the distinction between commonsense and technical meanings of statutory terms, it also has not considered whether a term’s meaning is vague, ambiguous, or open-textured as applied in a given set of facts, at least not from scratch. Here, “from scratch” means without some human expert or system designer having already manually specified which of a rule’s terms have been argued about in the past.
Instead, a long line of AI and Law systems have relied on human experts and system designers to manually specify in advance which of a rule’s terms can be or have been argued.[56] The terms serve as an index into a set of past cases in which courts have interpreted a term’s meaning in a given set of facts and decided whether the term applied or not.[57] The system uses those links to find relevant cases and generate arguments by analogy that the same result should apply in a current fact situation.
The ability of an AI system to detect these debatable issues and argue about them in the context of a particular fact situation depends on the availability of a corpus of cases, indexed by those issues which were argued about, and depends on a representation of their facts and those of the new problem. These programs represent the facts of cases not as texts but using certain factual features, such as criterial facts as in GREBE[58] or factors in the “hypo” line of programs (i.e., HYPO,[59] CATO,[60] CABARET,[61] IBP,[62] and VJAP[63] (the Value Judgment-based Argumentative Prediction program)).
A criterial fact is one that a court stated was important in deciding whether the term of a legal rule was satisfied in a particular case. GREBE represents a case as a semantic network with the court’s conclusions about the claim and its elements at or toward the topmost point of the graph and the facts the court deems criterial for its conclusion toward the fringe.[64] Figure 5 illustrates three criterial facts the court in Steinberg v. Petta regarded as important in concluding that the defendant could not have harbored or kept an animal.
Factors are stereotypical patterns of fact that tend to strengthen a side’s argument concerning a claim or element. Figure 6 illustrates some factors that might be important in determining if a defendant keeps or harbors an animal.
The system designers would have determined which terms had been subject to dispute in past cases and represented the case facts manually to enable the systems to make arguments by analogy. As noted, in the hypo line of programs, for example in VJAP, past cases are represented in terms of certain factors associated with the courts’ decisions whether legal terms were satisfied. In the GREBE program, criterial facts are used for this purpose. When the description of a new case is submitted—typically represented not as text but as a collection of such manually-represented factual features—the program determines which features are present in the new problem, matches it to past cases with similar features, and attempts to map the arguments about the debatable terms from the past cases to the new case. The programs make arguments by analogy that the term is or is not satisfied in the new case based on similar arguments in one or more of the retrieved past cases.
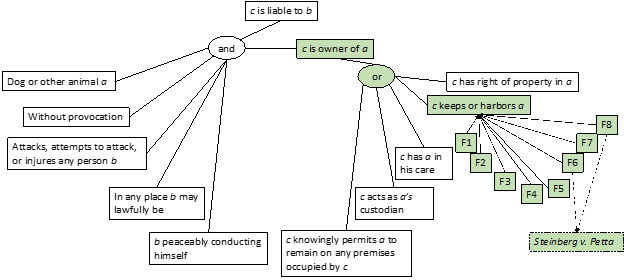
Figure 7 illustrates what a VJAP-type domain model of a dogbite claim’s elements might look like. A domain model is a graph of the elements employed in the legal rules for deciding a type of claim, the factors related to those elements, and the cases in which those factors apply. In the two-thirds of the figure toward the left, one sees the elements of the claim. One of the “OR” elements of the definition of the legal concept of “owner,” c keeps or harbors a, is connected to the set of factors in Figure 6. The factors are linked to cases in which they apply. For example, factors F6 and F8 are linked to the case of Steinberg v. Petta (i.e., the Steinberg case is indexed by factors F6 and F8).
If the VJAP program had been set up for the dog bite domain with a more complete model of elements, factors, and indexed cases, one could submit the hypothetical scenario to it. One would first have to represent the hypothetical as a list of the factors that apply in the hypothetical. Given a new case, also represented manually as such a list of factors, the VJAP program would follow the factors upward to the associated elements and downward to the indexed cases. Here, arguably, factors F1, F6, and F8 at the right in Figure 7 apply to the hypothetical scenario of Figure 1. This enables the program to determine that the element “keeps or harbors” is relevant in the problem. Given that factor F1 arguably applies, that is, JC allowed the dog to remain on her property and gave the dog a treat and some water, the conflict with F6 and F8 indicates this element is debatable.
AI approach to Step 6: Searching case law for clarity on questionable elements and sorting through cases for relevance and applicability to the client’s problem
As noted in Part II, Step 6 of this Article, searching case law involves finding cases that are factually similar to the hypothetical involving a non-owner caring for a dog that injures someone. As we saw in the AI approach to Step 2, the top-ten cases retrieved by Westlaw Edge all appeared to be relevant. One would still need to read the cases in order to determine which are the most relevant and how they bear upon the questionable elements for purposes of preparing the memo.
To what extent has AI automated that process of sorting cases by relevance? A search for case law involves many criteria. One is the similarity between the query and documents as measured by some metric such as TF-IDF, a metric proportional to the frequency of a query term in the case document and inversely related to the term’s frequency in the corpus of documents. Other criteria involve query expansion based on identified relationships between words in the corpus, proximity of query terms in case documents, precedential value of a case and treatment history, and frequency of citation of the case in a citation network. While these may not be AI techniques by themselves, services including LexisNexis and Westlaw Edge employ a learning-to-rank approach in which machine learning optimizes the weighting of such criteria given the nature of the search and the evident intention of the searcher and the question the searcher appears to be asking.[65] Analyzing textual queries for intent and for questions asked also involves natural language processing.[66]
Increasingly, text analytic tools are able to determine the issues for which a case has been cited, using a combination of citation networks, machine learning, and natural language processing. For instance, Figure 8 shows the output of the “How cited” tool of Google Scholar Cases for the Steinberg v. Petta case, which, as described above, turned up in a Westlaw search.
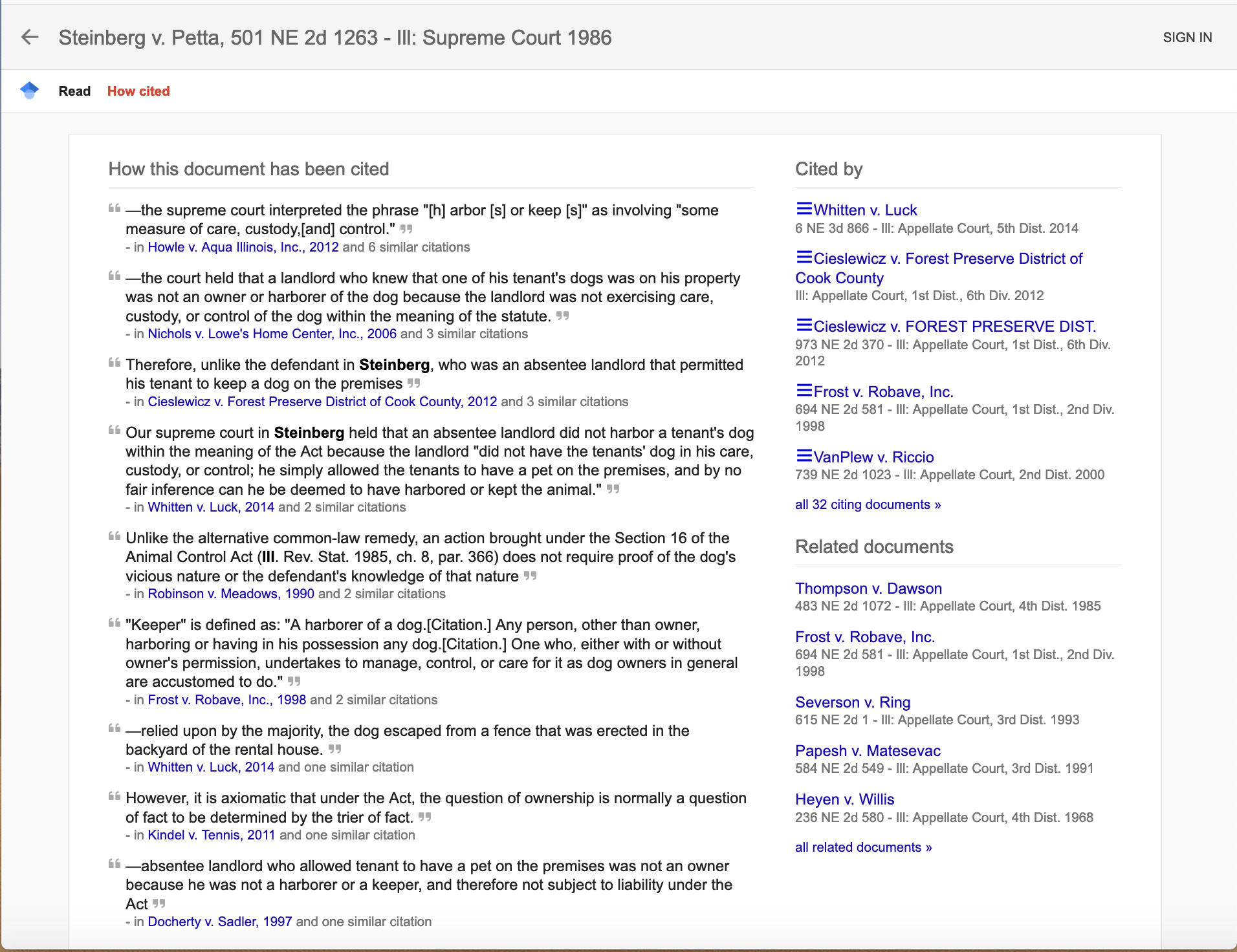
The “How cited” tool organizes the cases that cite Steinberg into groups or equivalence classes by the proposition for which they are citing the Steinberg case. Perusing the quotations illustrates the statutory concepts for which the case was cited, including some of the questionable elements in the hypothetical dogbite scenario of Figure 1. These include “harboring,” “keeping,” and “exercising care, custody, or control” and hint at some relevant facts in the cases for comparing with our scenario.
AI approach to Step 7: Synthesizing a rule from the relevant cases
As noted in Part II, Step 7 of this Article, synthesizing a rule from the relevant cases is a complex task for humans and even more so for AI. It involves 1) organizing the cases as to outcome, 2) analyzing the reasoning in each case to determine the principles or rules the courts used in reaching their decisions, and 3) synthesizing the case rules to formulate a rule that a court in the jurisdiction would apply in the client’s case. Recall the rule that a legal writing professor synthesized in Step 7 for deciding whether a caretaker is an “owner” and thus liable:
If the caretaker voluntarily assumed a significant level of care and control of an animal, similar to the level of care and control a legal owner assumes, such as feeding, providing water, and letting outside, the caretaker is an “owner,” but not if the caretaker performs only smaller actions, like occasionally providing food or water, if not required for the care of the animal; these do not rise to the level of care required for liability.
We know of no program that has ever managed to synthesize this kind of rule from case texts. As noted above, AI and Law programs have barely managed to formulate a rule to summarize the requirements from the text of statutory provisions, much less to summarize the requirements of multiple case texts.[67]
Figure 8 illustrates how Google Scholar Cases organizes cases citing a case whose citation a user has input. The organization is based on a citation network and on some ability to match the sentences that cite a case and their topics. It does not include information about the cases’ outcomes nor does it have any deep understanding of those sentences. It may quote the text of a rule or principle, but it does not understand that this text functions as a rule, a principle, or something else, and it cannot use it to synthesize a rule that would apply to the hypothetical or result in the desired outcome.
AI approach to Step 8: Analogizing and distinguishing searched cases
Similarly, comparing the facts extracted from the texts of cases to those of the text of the dogbite scenario is beyond the ken of existing AI programs. A program can identify matching or similar sentences and infer topics, but it can only infer in a limited way from the text what the facts of a case are, whether they are relevant to the facts of the scenario, or if they are stronger or weaker in favor of the plaintiff in a case or in the scenario. These would be key tasks in analogizing and distinguishing searched cases.
An above section, “AI approach to Step 5: Identifying any questionable elements,” introduced AI and Law work that has modeled legal argument with cases, including analogizing, distinguishing, and citing counterexamples to cases. As noted there, this work has assumed that relevant factors have been manually identified in the facts of the scenario and cases. As we will see in the next section, the analogies drawn by recent computational models of case-based reasoning like VJAP can even account for the values underlying an area of legal regulation and the effects of case decisions on tradeoffs of those values.
Assuming that someone had created a VJAP-type domain model of a dogbite claim’s elements like the one in Figure 7 and populated it with factors like those in Figure 6 and cases represented in terms of such factors, one could imagine a program generating arguments like the following:
→ Where defendant (F6) did no more than merely permit the presence of the animal on his/her premises and (F8) exercised minimal care, custody, or control of the animal, the defendant did not “keep or harbor an animal” and was not the owner of the animal. Steinberg v. Petta.
ß Steinberg can be distinguished. The defendant in the scenario (F1) exercised some measure of care, custody, or control of the animal when she allowed the dog to remain on her property and gave the dog a treat and some water. Where the defendant fed the dog and gave it water, and let the dog out into the yard, the defendant was an “owner” under the Illinois statute. Docherty v. Sadler.
These are some of the kinds of arguments that the programs early in the hypo line (i.e., HYPO, CATO, CABARET, and IBP) could generate based on comparing sets of factors. Again, this assumes that the problem and cases had been manually represented in terms of factors.
Extracting factors automatically from the texts of cases is a challenging research task.[68] Some encouraging progress has been reported in the SCALE project.[69] The researchers developed a scheme for labeling features keyed to the types of finding, issue, factor, and attribute sentences that arise in “domain name” dispute cases under the rules of the World Intellectual Property Organization (WIPO).[70] Their machine-learning approach has achieved some success in automatically identifying instances of such sentences in the texts of previously unseen domain name cases.[71] Another machine-learning approach has achieved some success in predicting factors that are present in the texts of trade secret cases from the VJAP corpus.[72]
In the not-too-distant future, if a traditional legal information retrieval (IR) system is employed and retrieves tens of cases, a legal app might analyze the texts of the cases and identify factors or other features with which it would rerank the cases according to measures of utility given the user’s scenario and goals. This assumes an interface with which the user can specify its goals in a manner that the system understands. In this way, a path is emerging toward connecting commercial legal IR systems with knowledge-based AI approaches, those that explicitly represent and reason with expert knowledge such as legal rules, elements, and factors.[73]
AI approach to Step 9: Predicting the outcome
We saw in Step 9 of Part II of this Article that a good attorney would consider the purpose of the synthesized rule in predicting what the outcome would be if a court applied the synthesized rule:
It seems a likely outcome that JC would not be considered an owner when the attack occurred because her friend dropped off the dog without JC’s knowledge, and JC had not voluntarily assumed owner-like responsibilities for the dog. The attorney would also have to consider and weigh possible counter-arguments—what actions did JC take, like relunctantly allowing the dog to remain and giving the dog water and a treat—that could constitute owner-like care and control. Finally, a thorough attorney would take into account the statute’s purpose—to compel people who have responsibility for an animal, even if not legal owners, to control the animal so that the animal does not injure someone.
This is a kind of reasoning AI and Law has modeled, for example, by the VJAP program, but again, it would only work if it were based on a VJAP-type domain model of a dogbite claim’s elements, complete with factors and cases represented in terms of such factors.
One additional component for VJAP is to represent the values underlying the legal regulation—here the Illinois statute regarding dogbites—and how the various factors affect each value, such as by making it more protected, indicating that it has been waived, making it less legitimate, or interfering with it. For example, two values that one imagines underlie the dogbite regulation are the following:
V1: to limit injuries due to animal bites by incentivizing individuals to exercise control over them.
V2: to avoid penalizing people for treating animals humanely.
Case decisions affect tradeoffs across these values. For instance, if the court had come to the opposite conclusion in the Steinberg case, holding that the absentee landlord, who merely allowed his tenants to keep their dog on the premises, was an “owner,” it would strengthen the protection of V1 but, arguably, at the cost of rendering V2 less legitimate. After all, is it fair to hold someone as distantly connected to a tenant’s animal as an absentee landlord responsible for all of the injuries the animal may cause? Perhaps it is, but the court did not so hold, which is part of the significance of the Steinberg decision.
The dogbite hypothetical implicates values V1 and V2. To hold JC liable would strengthen the protection of V1 but at the expense of rendering V2 less legitimate, a tradeoff for which the Steinberg decision could be cited as rejecting. In addition, such a decision would protect V1 at the expense of interfering with V2, penalizing JC for treating a dog humanely by taking care of it and giving it food and water. Thus, the argument above might be continued:
Docherty can be distinguished. The caretaker there had the express responsibilities of feeding the dog, giving it water, and letting it out into the yard. In the current case, JC simply gave the dog a bowl of water and a treat. To apply the result in Docherty would interfere with V2, penalizing someone for treating an animal humanely and would render V1 less legitimate.
If there were a precedent involving that same tradeoff between V1 and V2 in which the court held against liability, JC’s attorney could cite it in support.
The VJAP program begins to model such arguments. It associates factors with values and value effects; thus cases are indexed not only by factors but, in effect, by applicable values and effects on values. The effects on values become a measure of relevant similarity. Given a new problem, VJAP lines up the pro-plaintiff effects and the pro-defendant effects and selects the cases with the most similar tradeoffs. If a case involves the same factors as a problem, this increases the degree of match. Where the factors differ, it may reduce the degree of match to some extent. But those differences in factors might be outweighed by the same tradeoffs in values and such a case might be measured as more relevant than one with the same factors. Whereas CATO and IBP make a fortiori arguments based on set overlaps, VJAP makes the weightiest arguments based on how well a case explains the tradeoffs in the training set of cases in the corpus.[74] This involves factor overlap plus how well a case explains the tradeoffs in weights of value effects.[75]
Based on these weightiest arguments, VJAP predicts the outcome of a case and can explain its predictions in terms of the arguments. As explained above, however, applying VJAP to the dogbite problem would require that someone had assembled a set of factors, values, and cases for this legal domain. Until machine learning can extract factors from the case texts, assembling these items must be done manually.
Legal text analytics offers another way to predict the outcomes of legal cases. Researchers are applying machine learning algorithms, including deep learning neural networks, to predict outcomes of cases directly from textual descriptions of their facts.[76] Neural networks are made up of input and output nodes connected to one or more layers of intermediary nodes via weighted edges. Propagating an input to an output involves a linear combination of the weights. The goal of the network is to learn weights that minimize the deviation of the computed output with the target output. Different architectures of networks, layers, and depths are suitable for different tasks. Deep learning neural networks, which have multiple layers, are organized to learn from sequences of text.[77]
For example, researchers have applied such networks to decisions of the European Court of Human Rights.[78] The machine learning (ML) algorithm predicts if the court found a violation and of which provisions.[79] This would be like submitting a natural language description of the facts, as one does to Westlaw Edge, but with a program now predicting an outcome.
A requirement for applying this text-based ML prediction approach is assembling a large collection of case texts concerning animal bites. Supervised machine learning requires labeled data for training.[80] For example, Chalkidis et al. employed nearly 8,500 cases for training and development and 3,000 cases for testing.[81] One does not need to identify legal knowledge such as elements or issues, factors, and values, as one would for VJAP.
On the other hand, the text-based ML prediction method could not explain its predictions; VJAP can generate such explanations. Although the neural network approach could accurately predict outcomes, without legal knowledge of elements, issues, factors, or values, it would not be able to explain its predictions in terms lawyers are likely to understand. The information the neural networks learn from the large case text corpus is in the form of weights distributed across the network. It does not correspond in any direct way to human legal knowledge and cannot easily be extracted to explain a prediction.
Researchers are attempting to tease out from neural networks the constituents of legal explanations.[82] For example, one kind of neural network approach, hierarchical attention networks (HANs), learns from case decision texts to predict outcomes of new cases and can assign attention scores to the most predictive parts of texts.[83] HANs layer the networks: one layer operates at the word level and extracts predictive words into a sentence representation.[84] Another operates at the level of the resulting sentences and represents predictive aspects of the whole document.[85] For present purposes, the attention model is the important point. It assigns higher weights to the text portions that have greater influence on the model’s outcome prediction.
The hope is that the highlighted portions explain the prediction so that humans can readily understand.[86] Recent experiments with human experts, however, suggest that these highlighted, high-scoring portions of texts fall short of meaningful explanations.[87] In fact, one motivation for the SCALE project, discussed above,[88] was to address this deficiency of explanation using HANs by automatically identifying factors in case texts that could augment explanations of a prediction.[89]
AI approach to Step 10: Writing the office memorandum
The final question is whether an AI program could put all of this information together to write a legal memorandum.
One impetus for this Article involved some surprising recent developments in the ability of programs to generate narratives using language models and transformers.[90] A language model is a neural network that has been trained to predict the next word in a sequence of words.[91] The inputs to the language model are a sequence of words such as, “The defendant cannot be deemed to have harbored or kept an animal, where he was an absentee _______.” Its output is a prediction of the next word in the sequence, for example “landlord.” A transformer, a kind of neural network architecture, can learn associations between words that might be relatively far away from each other in complex sentences.[92] It employs an attention mechanism for this purpose.[93] Given an input sequence, each layer of its network assigns more weight to some features than to others. By making multiple, parallel connections between certain words while ignoring others, it develops a “treelike representation of sentences [which gives] transformers a powerful way to model contextual meaning . . . .”[94] Such a program does not understand the term “absentee landlord,” but its statistical information can predict that “landlord” very likely follows “absentee” in the context of the above sentence.
OpenAI has developed a number of language models including GPT-2 and more recently GPT-3.[95] These are unidirectional models; that is, they read and compile frequency information about associations of words from left to right.[96] Other language models like BERT are bidirectional; they read and compile frequency information from left to right and right to left.[97] GPT-3 learns its frequency information for predicting the next word in a series from a dataset containing an enormous amont of English text extracted from the World Wide Web including Wikipedia, the “Common Crawl,” and Webtext2.[98] Its attention function calculates the probability that a word will appear given the preceding words and stores this frequency information in 175 billion parameters.[99]
A virtue of the OpenAI language models is that they can use their frequency information to generate meaningful sentences.[100] A version of the GPT-2 language model powered an online transformer into which one could submit a narrative to which the transformer will append text.[101]
What happened when we submitted to GPT-2 (i.e., talktotransformer.com) the description of the dogbite scenario of Figure 1 plus the prompt, “JC consulted her attorney, who advised her . . . .”? It simply appended a few words, for example, “We begin our analysis.” Since the text of the hypothetical apparently was too long to process, we tried a shorter text and examined three responses at the top of Figure 9. While no first-year law student would be tempted to turn in any of these responses to their legal writing instructor, they are interesting. In each response, the transformer predicted a reasonable appearing, if irrelevant, phrase to complete the last sentence of the input: “JC consulted her attorney, who advised her . . . .” The second and third responses, at least, appeared to deal with “legal” topics.[102]
By contrast, GPT-3 is accessible only by application to OpenAI. Eight months later (in April 2021), after OpenAI granted GPT-3 access to a colleague, we asked him to submit the same queries. For the shorter query, GPT-3 generated the response at the bottom of Figure 9. It is just as fanciful as those of GPT-2, although it does focus on the possibility that JC could be sued.
One sign of progress, however, was that GPT-3 could process the longer query consisting of the full hypothetical scenario of Figure 1 and the prompt, “JC consulted her attorney, who advised her . . . .” GPT-3’s response is shown in Figure 10. The first paragraph is remarkable for a number of reasons. First, GPT-3’s completion of the prompt seems apt; it appears to be a reasonable facimile of legal advice. Second, it is tailored to the circumstances of the hypothetical. Unlike question answering systems, GPT-3’s response specifically refers to JC and MB in their roles in the hypothetical. Third, although GPT-3 does not cite legal sources such as Illinois statutes or cases to anchor its advice, it does quote two legal phrases in an apparently appropriate way: “unreasonable risk to human safety” and “loss of a normal life.” While there is no indication of where these phrases came from, a Google search indicates that the former phrase appears in materials concerning hazardous materials and the latter in Illinois jury instructions concerning damages.[103] It also appears in a website for a Chicago dog bite lawyer.[104]
Despite GPT-3’s impressive performance, no attorneys need fear for their jobs, at least not yet. GPT-3’s output is far from a legal memorandum. It does raise the question, however, of whether and how GPT-3 could be trained to write a legal memorandum. As it happens, GPT-3 can learn to perform some tasks when provided a natural language prompt that contains even just one or a very few training examples. This “few-shot ‘in-context’ learning . . . allows users—even those without technical expertise” to retrain the learning model.[105] It will be interesting to see if and how one can train GPT-3 to improve its response by modifying the prompt and providing examples.
In the meantime, some new legal apps may be helpful in reviewing a draft legal memorandum. One can submit a draft memo to an AI program like Casetext’s CARA A.I. to obtain suggestions about additional cases to cite. In the discussion of the “AI approach to Step 2,” we submitted the dogbite scenario to Casetext by cutting and pasting the Figure 1 hypothetical into the search box. As noted, one can also upload a brief via the “Search with a document” feature in order to find legally and factually relevant cases with Casetext’s CARA A.I.[106] Upon submitting the completed draft of a memo in the Appendix (on May 24, 2022), the program responds: “What issue or fact do you want CARA A.I. to focus on? Enter an issue or fact . . . .” It suggests various issues, including, “animal control acts,” “standard of care,” “duty of care,” “legal owner,” “civil damages,” as well as offering “all suggested cases.” Upon selecting “legal owner,” it provided “[t]op cases recommended by CARA A.I.,” noting that the “[r]esults [are] contextualized to the Legal Memorandum.pdf [Appendix] and your search terms.” A number of the top-ten cases appeared to be useful. CARA A.I. probably suggests them based on citation networks and issue topics of paragraphs containing citations.
Westlaw Edge’s Quick Check[107] and Lexis+ Brief Analysis[108] are similar tools. Upon uploading a draft brief or memo, each generates a report. Quick Check’s report recommends cases and other sources for each named section of the memo, provides warnings about cited sources, and analyzes quotations for accuracy. Its five recommended cases all related to the issue of ownership of the dog and had not already been cited in the memo. In addition, it recommended two briefs as similar to the submitted memo. Brief Analysis extracted twenty-five concepts from the memo including Ownership, Legal Owner, and Assume Control. From the twenty-seven recommended cases and seven treatises, it quoted at least fifteen relevant passages on the issue of ownership from cases not included in the memo.
AI legal apps are moving in the direction of automatically generating memoranda of law. Based on CARA A.I., Casetext’s Compose is generating first drafts of memoranda supporting particular types of motions, for example, motions to “quash a subpoena, exclude expert testimony, file a motion for protective order or compel discovery or disclosure.”[109] Presumably, each type of motion has an associated template that provides a framework of issues and boilerplate language for automatically generating textual arguments citing jurisdictionally appropriate statutes and cases relevant to each of the issues. Given the apparent limitations of language-model-based generation of narratives, such frameworks are probably necessary if they are to generate legal memoranda.
What will it take for transformer language models to generate better narratives than we saw in Figures 9 and 10? For one thing, the corpora on which GPT-2, GPT-3, and other language models have been trained probably do not (yet) include legal decisions and memoranda. It would be interesting to see what the GPT-3 language model could accomplish with additional training and a more relevant corpus.[110] Nevertheless, “the hurdle to generate authentic long texts is still high.”[111] The legal memorandum in the Appendix is over 3000 words long, while the most relevant part of GPT-3’s response is less than 150 words.
For another reason, even if GPT-3 had access to legal decisions and memoranda, there is still the problem that “machines don’t really understand what they’re writing (or reading).”[112] This is problematic, since GPT-3 can create snippets whose “style is [so] legalistic and facially convincing” that despite its “suspicious content,” “legal experts . . . are . . . uncertain about determining whether a legal opinion [snippet] is machine-generated or written by humans.”[113]
Transformer language models lack the conceptual structures that humans employ in reading or writing domain-specific texts. In Part II of this Article, we saw how humans would write a memo like that of Appendix A, or at least, how we would teach first-year law students to do so. In describing the steps of this process, it is natural to refer to conceptual legal categories and structures. These include, but go beyond, such legal claim- or statute-specific topics as “provocation,” “owner,” “harboring,” “care,” “custodian,” or “knowingly permit.” They include concepts for working with “legal regulation,” such as “statute,” “statutory law,” “case law,” “governing law,” or “legal rule” and rule “elements.” In addition, they include the working concepts and structures of interpreting and arguing about what legal rules mean and how they apply to facts, such as “relevant facts,” “legal question,” “questionable” elements, “synthesizing” a rule, “analogizing” and “distinguishing” cases, and “office memorandum.” They also include common sense concepts about which the programs have no knowledge, such as dogbites, care for dogs, the nature of dogs and human behavior with respect to dogs, or owning a dog. Finally, as noted above, the programs have no knowledge of the distinction between legal concepts and their common sense “counterparts,” such as “owner” as defined in the statute versus “owner” in common parlance.[114]
Concepts and structures like these are a necessary part of the way we describe how humans would read, understand, or write a memo like that of the Appendix. We would naturally speak of readers or authors as identifying, applying, and manipulating patterns of these concepts and structures in order to create or interpret the text.[115]
Presumably, these cognitive models arise through education. Law students may learn to identify, apply, and manipulate such patterns of conceptual structures through repetition and practice in law school; in a sense they may tune their more general models of reading and language to the demands of the legal domain.[116]
Can language models and transformers work if they do not understand the conceptual structures that law students learn to use? Can exposure even to millions of examples of legal memoranda or decisions enable programs to develop cognitive models or their machine equivalents? Or, can an extended series of well-designed few-shot training episodes enable a transformer model to learn to construct a legal memorandum like that in the Appendix? Perhaps eventually, but as yet, that does not seem to be the case.
IV. Implications for Teaching Legal Writing
All of this leads us to a few tentative conclusions about the implications of the development of AI and Law for the teaching of legal writing. It should be clear that AI is not poised to take over entry-level law positions. AI is not in the foreseeable future going to replace lawyers. It might be, however, that lawyers familiar with and facile with AI will replace lawyers who are not. How do we as legal educators, and specifically as legal writing teachers, introduce students to the ways that AI can now make their work more efficient and more accurate? It seems to us that there are at least two areas worth exploration.
First, and more importantly the impetus for this Article, the legal writing classroom needs modifications to introduce students to and to incorporate the possibilities of AI contributing to the task of writing an office memorandum (and perhaps other basic documents). Here, for example, is one of many possible ways in which students working with AI might work through the steps required to write an office memorandum:
-
Hybrid Step 1. Manually develop statement of hypothetical and/or frame legal question.
-
Hybrid Step 2. Submit full-text hypothetical in natural language query to Westlaw Edge or Casetext, or submit framed legal question to ROSS-type question answering system (if available).
-
Hybrid Step 3. Read Westlaw Edge, Casetext outputs of cases and statutes to see how they frame the legal question and bear upon it.
-
Hybrid Step 4. Manually pull out macro rule’s elements. Casetext’s CARA A.I. may indicate issues (for a submitted draft memo) as may Lexis Answers (if applicable).
-
Hybrid Step 5. Manually apply client’s facts to the elements.
-
Hybrid Step 6. Manually identify any questionable element given hypothetical’s facts. Following up on Casetext’s CARA A.I.'s issues (for a submitted draft memo) may indicate questionable elements.
-
Hybrid Step 7. Manually search with keywords case law from Westlaw Edge or Casetext to find cases that are factually similar to the hypothetical involving a non-owner caring for a dog that injures someone. Read these cases in order to determine which are the most relevant and how they bear upon the questionable elements for purposes of preparing the memo.
-
Hybrid Step 8. Manually synthesize a rule from the multiple relevant cases.
-
Hybrid Step 9. Manually analogize and distinguish searched cases (comparing the client’s facts to the facts in the cases).
-
Hybrid Step 10. Manually predict the outcome in the hypothetical.
-
Hybrid Step 11. Manually write the office memorandum. Optionally, upload drafts to Casetext’s CARA A.I., Westlaw Edge Quick Check, or Lexis+ Brief Analysis for suggestions of additional issues or cases.
This hybrid process for writing a legal memorandum is not radically different from the above ten-step process for (manually) preparing a legal memo.[117] Instructors can integrate the use of AI tools into the process while preserving the narrative description of cognitive models of legal reasoning: identifying facts, applying them to elements, synthesizing a rule from relevant cases, and analogizing and distinguishing cases.
Second, the legal writing classroom should convey some basic instructional overview of emerging possibilites for AI and Law-related jobs, such as the “human experts” or system designers who organize and manage the reading, analysis, and annotation of a corpus of statutory and case law. What we do know for sure is that new attorneys will need familiarity with AI techniques because AI will be increasingly utilized in law practice, and the machine learning involved requires extensive human intervention; someone must define the task that machine learning will perform, assemble and preprocess the data, design the types of classifications to be made, label (or annotate) a training set of data in terms of theses classifications, apply the machine learning algorithm, evaluate the results, and investigate the errors. A technical staff person may perform much of that, but not without the collaboration of attorneys who understand the technology as well as how to apply it in solving legal problems, how to evaluate the results, and whether to rely on them. Teaching those skills and knowledge to law students will require a paradigm shift in the discipline of legal writing, just as adapting to the dominance of computer-assisted legal research has required a paradigm shift in the teaching of legal research. It might well be that students who cannot effectively interact with and use AI will be ill-prepared for law practice.
Third, legal writing professors might fruitfully collaborate with other law professors and computer scientists who are already developing and teaching courses designed to introduce law students to the possibilities of AI in law practice. One example is the course that one of the authors of this Article is already teaching. Here is a brief description:
At the University of Pittsburgh School of Law, the author (a law professor) and a computer scientist co-teach a semester-long course entitled “Applied Legal Analytics and AI” to a class combining law students and undergraduates or graduate students in computer science or engineering.[118] The course introduces students to applying machine learning and natural language processing to extract information from legal textual data and provides gradual practice in tackling incrementally more complex tasks. Students experience the ways that text analytics have been applied to support the work of legal professionals and the techniques for evaluating how well they work. The course culminates in small team projects in applying machine learning and data analytics to legal problems.
As an example of integrating legal writing instruction and text analytics, the first homework assignment introduces students to using a legal question answering system in an exercise in legal research and memo writing. The LUIMA system, a prototype legal question answering system one of the instructors developed, accepts questions dealing with veterans’ claims for compensation for posttraumatic stress disorders (PTSD) and retrieves answers (i.e., extracted sentences similar to the question) from a database of decisions of the Board of Veterans Appeals. As a way to introduce the non-law students to some legal system basics, and as a refresher for the law students, they all read excerpts from an informative text authored by two veteran legal writing instructors.[119] The excerpts cover reading and briefing cases, using statutes, synthesizing cases, and drafting a legal memorandum and introduce basic legal concepts such as burden of proof, standard of proof, presumption, and preponderance of the evidence. With this as a guide, students read and brief a decision of the Board of Veterans Appeals, access LUIMA to answer legal questions about a problem scenario, and use the results of their legal research with LUIMA to write a short legal memorandum analyzing the problem.
In this way, the first homework assignment gives students a chance to work with a basic AI legal question answering system and to experience using the system to perform legal research and writing. In the remainder of the course, they learn the basics of how such a legal question answering system works.
V. Conclusions
Experienced legal writers understand the tools available for research, and for each tool they develop a sense of the information that tool is likely to find and the information it may miss. Legal writing instructors introduce law students to these tools and help them to begin to appreciate their utility, their strengths, and their limitations. With the advent of AI tools and the application of text analytics to legal documents, it has become considerably harder to understand how the tools work and how to assess their results, especially in the face of extraordinary claims for their capabilities.
In this Article, we have attempted to apprise legal writing instructors about how these tools can be applied, what they can do, and what they cannot do. We have illustrated some ways in which the tools could be integrated into the familiar lessons in legal writing. Our hope is that this suggestion of the melding of traditional legal writing teaching and AI will open a much larger conversation about how we might introduce the possibilities of using AI to our legal writing students.
Appendix
MEMORANDUM
To: Supervising Attorney
From: Associate
Date: October 5, 2019
Re: Jaime Castro’s liability under Illinois’s Animal Control Act
QUESTION PRESENTED
Under the Illinois Animal Control Act, is Jaime Castro liable for injuries Matt Bevers sustained when a friend’s dog, left on Castro’s property without her knowledge or explicit consent, bit Bevers’s hand?
BRIEF ANSWER
Probably no. Castro will not be liable for the injuries Bevers sustained. The Illinois Animal Control Act holds the owner of the animal liable in civil damages for any animal attacks or injuries as long as the animal, without provocation, attacks, attempts to attack, or injures any person who is peaceably conducting themself in any place where they may lawfully be. An owner is defined as someone who knowingly and voluntarily consents to care for an animal, even if not the legal owner. In this case, the dog attacked Bevers without provocation while Bevers peaceably conducted himself at the party to which Castro invited him. A court will likely hold, however, that Castro is not liable for Bevers’s injuries because she did not voluntarily assume responsibility to manage, care for, or control the dog in a manner that owners would generally be accustomed, regardless of the amount of time the dog had been in her care previously.
FACTS
Our client, Jaime Castro, anticipates that Matt Bevers will sue her. Bevers, a professional videogamer, claims he will sue for injuries sustained from a dog bite he received on Castro’s property.
Castro lives in a home with her housemate, Ilana Wexler. Their friend, Abbi Abrams, has a greyhound licensed in Abrams’s name. Oftentimes, Abrams would leave her dog at Castro’s and Wexler’s residence. Castro and Wexler kept dog treats for Abrams’s dog, indicating the frequency that Abrams would leave her dog there.
Castro planned to have a viewing party on August 5, 2019, for the Cubs-White Sox series. She left earlier in the day to the grocery store, and she returned home around 3 p.m. At home, she found Abrams’s dog alone in the backyard. She had not known that Abrams was going to leave the dog that day. She provided the dog with a treat and some water.
Because the party would be happening in her backyard, Castro kept the dog indoors and closed the doors to the house. She placed a sign on the front door that indicated to guests to go around the house to the back to enter the party.
Guests arrived at the party, and they all entered the backyard through the back of the house instead of through the front door. Bevers arrived with a plate of chicken, and unlike the other guests, he entered the home through the front door. As he exited the home to the backyard, the dog ran between his legs causing him to lose his balance and drop the chicken. The dog tried to eat the chicken but instead bit Bevers’s hand. From the bite, Bevers sustained an injury to his thumb and index finger, causing an injury that required Bevers to receive seven stitches in his hand.
Bevers threatened to sue Castro for damages, including his medical bills, as well as the losses incurred from his inability to play videogames as a result from his injury.
DISCUSSION
The Illinois Animal Control Act seeks to encourage tighter control on animals to protect the public from harm. Docherty v. Sadler, 689 N.E.2d 332, 334 (Ill. App. Ct. 1997). The statute explains what qualifies as an animal attack:
If a dog or other animal, without provocation, attacks, attempts to attack, or injures any person who is peaceably conducting himself or herself in any place where he or she may lawfully be, the owner of such dog or other animal is liable in civil damages to such person for the full amount for the injury proximately caused thereby.
510 Ill. Comp. Stat. Ann. 5/16 (West 2006).
A plaintiff must show that the animal attack occurred while they peaceably conducted themself, that they did not provoke the animal, and that they were in a place they could lawfully be. In the present case, the encounter between Bevers and the dog satisfies the elements that qualifies an attack under the statute. Bevers peaceably conducted himself at the time of the incident. He entered the home through the front door and exited to the backyard through the back door in order to enter the party. Bevers did not provoke the dog when it bit him. He dropped a plate of chicken, and when he reached to pick it up, the dog bit his hand while attempting to eat the chicken. Castro invited Bevers to the party, so he lawfully could be there. Thus any person who qualifies as the dog’s owner is likely liable to Bevers.
The question remains whether Castro qualifies as an owner under the Illinois Animal Control Act. The statute provides a definition of an owner:
Owner means any person having a right of property in an animal, or who keeps or harbors an animal, or who has it in his care, or acts as its custodian, or who knowingly permits a dog to remain on any premises occupied by him or her.
510 Ill. Comp. Stat. Ann. 5/2.16 (West 2006). Furthermore, Illinois courts have required more than passive involuntary care. Instead, for owner liability, they require that a person voluntarily care for the animal when an injury occurs and that the person actively demonstrate the care by an act such as feeding. Thus, a court will probably not hold Castro liable for the injuries Bevers sustained from the dog attack because she did not voluntarily assume responsibility to manage, control or care for the dog in a manner that owners would generally be accustomed.
A. Under the Illinois Animal Control Act, Jaime Castro does not qualify as an “owner” because she did not voluntarily care for the dog when the bite occurred.
Illinois case law establishes that an individual qualifies as an owner of an animal if they voluntarily assume a measure of responsibility to care for an animal and have the responsibility to manage or exert their control over the animal in a manner to which owners would generally be accustomed, regardless of the amount of time the animal is in the person’s care or the person’s previous interactions with the animal. Care consists of providing food, water, and letting the animal outside, which constitutes more than passive ownership of the animal. Steinberg v. Petta, 501 N.E.2d 1263, 1265 (Ill. 1986); Beggs v. Griffith, 913 N.E.2d 1230, 1235 (Ill. App. Ct. 2009); VanPlew v. Riccio, 739 N.E.2d 1023, 1024 (Ill. App. Ct. 2000); Severson v. Ring, 615 N.E.2d 1, 4 (Ill. App. Ct. 1993); Docherty, 689 N.E.2d at 334.
Illinois courts require a measure of care and custodianship that demonstrates more than passive ownership of the animal in order to be the owner. Steinberg, 501 N.E.2d at 1266; Severson, 615 N.E.2d at 4. In Steinberg, the court held that the defendant did not qualify as an owner when he, an absentee landlord, allowed his tenants to keep a dog on the premises, and the dog bit the plaintiff. Steinberg, 501 N.E.2d at 1266. The court characterized the allowance of the dog on the premises as “passive ownership,” which did not satisfy the measure of care as dog owners customarily assume. Id. Similarly, in Severson, the court held that the defendant did not qualify as an owner when she allowed a friend to chain his dog to a tree in her backyard, and it attacked a child on her property. Severson, 615 N.E.2d at 4. Though the defendant and her boyfriend checked the dog’s food and water, they did not need to for its care. Id at 3. The court reasoned that because the defendant did not need to provide food or water, nor do anything necessary for the care of the dog, she did not fulfill the measure of care for an owner. Id.
The measure of care pursuant to ownership includes feeding the animal, providing water, and letting the animal outside. VanPlew, 739 N.E.2d at 1026; Docherty, 689 N.E.2d at 335. In VanPlew, the court held that the plaintiff met the standard of care that made her an owner under the statute when she assumed the responsibilities of feeding the dog, giving it water, and letting it outside while its legal owner went on vacation. VanPlew, 739 N.E.2d at 1025. While fulfilling her responsibilities towards the dog, it bit her. Id. The court held that because she had the specific responsibilities of care towards the dog including providing it with food and water, and letting it outside, she provided necessary care, and undertook custody in a manner that owners would generally assume. Id. at 1026. Similarly, in Docherty, the court held that the plaintiff qualified as an owner when a dog belonging to his absent neighbor injured him while under the plaintiff’s care and control. 689 N.E.2d at 333. The court held that because he had the express responsibilities of feeding the dog, giving it water, and letting it out into the yard, he had the “status of owner.” Id. at 335.
To be an owner, Illinois courts include voluntariness as an element to an individual’s care, custody or control over the animal. VanPlew, 739 N.E.2d at 1026; Docherty, 689 N.E.2d at 335. The court in VanPlew held that the plaintiff qualified as the owner when she took the job to pet sit for the defendant while the defendant travelled. 739 N.E.2d at 1024. The court reasoned that because the plaintiff voluntarily placed herself in a position of control akin to an owner, she had custody over the dog at the time of the injury. Id. at 1026. Similarly, the court in Docherty held that the plaintiff had ownership of the dog when he explicitly agreed to take on the responsibilities of care for the defendant’s dogs while the defendant traveled. 689 N.E.2d at 333. The court reasoned that because he voluntarily took control of the dogs, he had custody over them at the time of injury. Id. at 335.
Although no Illinois courts have ruled over a case in which a party had involuntary care or control over an animal, the defendant in Rodriguez v. Cordasco, a New Jersey case, did not expressly assume control over stray dogs on her property, and the court found that the defendant did not qualify as the owner under the New Jersey statute. 652 A.2d 1250 (N.J. Super. Ct. App. Div. 1995). The stray dogs merely remained on her property, and she sporadically fed them, and, therefore, she did not "owe a duty of care to the public to protect against the action of those dogs."Id. at 1252. When the stray dogs ran from her property and chased the plaintiff, she did not have liability over them. Id. The court reasoned that the defendant’s sporadic feeding did not make her an owner or qualify her as a keeper of the dogs because she did not expressly assume management, care, or control over the dogs. Id. at 1253.
If someone voluntarily assumes control or management of an animal and does not exercise that ability to control or manage an animal to the degree an owner would be accustomed, he or she is liable as an owner. Beggs, 913 N.E.2d at 1237. In Beggs, the court held that the defendant had the status of owner when a prospective buyer of his property sustained injuries on his property from the defendant’s friend’s horses. Id . The defendant voluntarily gave his friend’s horses access to his land and barn for their care while still maintaining the ability to control when the horses could be on his property. Id. at 1236. The court reasoned that because he chose not to exercise his control over the horses by preventing them from having access to his barn when the plaintiff visited, and because he facilitated the plaintiff’s visit, he qualified as an owner. Id at 1236–37. Conversely, in Rodriguez, the New Jersey court ruled that the defendant’s actions of feeding the stray dogs did not give her the duty to assume control over them to protect the public, so she did not have to exert control over the dogs as the plaintiff passed her house. 652 A.2d at 1252.
Castro’s care and custodianship of the dog could be characterized as passive ownership by Illinois courts. In Steinberg, the court held that the defendant was not an owner because he merely allowed his tenant’s dog to remain on the premises. 501 N.E.2d at 1266. Similarly, at the moment of the attack, Castro merely allowed the dog to remain on her property, so as in Steinberg, a court will likely hold that this level of care does not fulfill a measurement of care for the dog beyond passive. Bevers could argue that unlike the defendant in Steinberg, Castro did provide some care to the dog when she gave it a treat and water. However, Castro providing the dog with a treat and water does not provide a dog necessary care pursuant to ownership. Similarly, the court in Severson ruled that the defendant was not the owner because she did not need to provide food or water, nor do anything necessary for the care of the dog besides allow it to remain chained in her backyard. 615 N.E.2d at 4. A court will likely hold that Castro is not an owner because, like the defendant in Severson, she did not need to provide a treat and water to the dog for its care.
The level of care that Castro gave the dog does not fulfill the standard that Illinois courts established for an owner including feeding the animal, providing water to the animal, and letting the animal outside. The courts in VanPlew and Docherty ruled that the plaintiffs were both owners because they assumed the responsibilities of feeding the dogs, giving them water, and letting them outside, so they fulfilled the standard of care necessary to be an owner. VanPlew, 739 N.E.2d at 1024; Docherty, 689 N.E.2d at 334. Conversely, Castro only provided the dog with water and a single treat. Bevers could argue that this constituted a level of care that an owner would be accustomed to giving. However, Castro did not let the dog out as in the cases of VanPlew and Docherty. Once she brought the dog inside the home, she did not let him out for his care. Also, it can be argued that a treat does not qualify as food akin to the substantive food provided to the dogs by the plaintiffs in VanPlew and Docherty. Courts would likely hold that she does not qualify as an owner because unlike the plaintiffs in VanPlew and Docherty, she did not fulfill all three elements of the measure of care pursuant to ownership.
Castro does not qualify as an owner of the dog because she did not voluntarily assume care, custody, or control over the dog. In both VanPlew and Docherty, the plaintiffs placed themselves in positions analogous to owners when they voluntarily assumed the roles as pet sitters while the legal owners were not home. VanPlew, 739 N.E.2d at 1024; Docherty, 689 N.E.2d at 334. The plaintiffs in these cases voluntarily took on these roles with express knowledge of their duties of care towards the dogs, so the courts found them both liable as owners under the statute. VanPlew, 739 N.E.2d at 1024; Docherty, 689 N.E.2d at 334. In VanPlew, the plaintiff had an agreement to provide her services of care to the dog for money. VanPlew, 739 N.E.2d at 1024–23. Conversely, Castro did not give express agreement to care for the dog when she came home and found the dog in her backyard. Bevers could argue that Castro, unlike the plaintiffs in both Docherty and VanPlew, had cared for the dog on occasions previously, so she gave implicit consent for the care of the dog. Illinois courts have not considered a case involving involuntary care of a dog; in a New Jersey case, however, a court did not hold the defendant liable for dogs when they chased the plaintiff, although the defendant had a history of providing food for stray dogs on her property. Rodriguez, 652 A.2d at 1252. The court in Rodriguez ruled that feeding the dogs when they would come on property did not constitute ownership. Id. at 1252. Similarly, Castro did provide care for the dog in the past, but she, like the defendant in Rodriguez, did not give express consent to the dog being on her property at the time of the attack, so Illinois courts may rule that she is not an owner.
Castro did not voluntarily assume control over the dog, but she did exercise her ability to control the dog in order to protect her guests, so she should not be liable as an owner of the dog at the time of the attack. In Beggs, the court held that the defendant was an owner because he did not exercise his control over the horses on his property to prevent them from accessing his barn when he knew the plaintiff would be on his property. Beggs, 913 N.E.2d at 1236. In addition, the defendant solicited the plaintiff as a potential buyer of his property, so he placed her on in the same location as the horses that harmed her. Id at 1236–37. Similarly, Castro invited Bevers to her party, but unlike the defendant in Beggs, Castro did not assume control voluntarily, and she did exercise her ability to control the dog to protect her guests. Castro controlled the dog by keeping him inside the house to prevent interaction between the dog and the guests attending the party in the backyard. In addition to her control over the dog’s location, Castro placed a sign on the front door indicating to guests to enter the party through the back of the house, supporting her intention to keep the dog away from the guests. It can be argued that Castro did not have a duty to control the dog, and she provided a public service by trying to control the dog. The court in Rodriguez held that the defendant had no duty to protect the public by assuming control over the stray dogs. Similarly, Castro found the dog on her property upon returning home, and she had no duty to protect her guests from it. Illinois court will likely hold that Castro does not qualify as an owner because she did not voluntarily assume control over the animal, so she did not have the duty to control the dog.
CONCLUSION
The Illinois Animal Control Act holds animal and dog owners liable to civil damages if the animal attacks another person. Castro can concede that the dog attacked Bevers without provocation while Bevers peaceably conducted himself in a place that he could lawfully be. She will probably be able to establish that she is not the legal owner of the dog under the Animal Control Act even though the dog was on her property. She can establish that she did not provide adequate care in a manner that would generally be assumed by an owner. She can argue that the dog was there without her consent so she involuntarily cared for it. Finally, Castro did not voluntarily assume control over the dog but did attempt to control it by keeping it indoors. She intended to keep the dog away from the guests by keeping the dog indoors and by placing a sign on the front door to keep the guests from entering the home. For these reasons, Castro was not the legal owner of the dog at the time the attack occurred, and she should not be held liable under the Illinois Animal Control Act.
Paul D. Callister, Law, Artificial Intelligence, and Natural Language Processing: A Funny Thing Happened on the Way to My Search Results, 112 Law Libr. J. 161, 172 (2020) (“Brief analysis is also a feature of Westlaw Edge, Casetext, Ross Intelligence, and several other vendors’ products. Actually writing the brief may not be far behind.”).
John McCarthy, Marvin L. Minsky, Nathaniel Rochester & Claude E. Shannon, A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence, August 31, 1955, 27 AI Mag., no. 4, at 12, 12 (2006).
Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age 4 (2017).
Id. at 5; see also Kevin D. Ashley, Automatically Extracting Meaning from Legal Texts: Opportunities and Challenges, 35 Ga. St. U. L. Rev. 1117, 1117 (2018).
Zhi-Hua Zhou, Machine Learning 2 (Shaowu Liu trans., 2021).
Ryan Whalen, Legal Networks: The Promises and Challenges of Legal Network Analysis, 2016 Mich. St. L. Rev. 539, 548–52 (2016). The Ravel tool, now part of LexisNexis’s Context, employs citation networks. Ravel Law, https://www.ravellaw.com/ [https://perma.cc/Q6P3-5RWA] (last visited Apr. 30, 2021).
John Prager, Eric Brown, Anni Coden & Dragomir Radev, Question-Answering by Predictive Annotation, in SIGIR '00: Proceedings of the 23rd Annual International ACM SIGIR Conference on Research & Development in Informational Retrieval 184, 184 (2000).
ROSS Intelligence, https://rossintelligence.com [https://perma.cc/7LAK-H4GW] (last visited Apr. 30, 2022). See infra note 32 and accompanying text.
See Ivy Wigmore, Artificially-Intelligent Attorney (AI Attorney), https://www.techtarget.com/searchenterpriseai/definition/artificially-intelligent-attorney-AI-attorney [https://perma.cc/K4AQ-A4XP] (last visited Apr. 30, 2022); Dana Remus & Frank Levy, Can Robots Be Lawyers? Computers, Lawyers, and the Practice of Law, 30 Geo. J. Legal Ethics 501, 503 (2017).
Michael Simon, Alvin F. Lindsay, Loly Sosa & Paige Comparato, Lola v. Skadden and the Automation of the Legal Profession, 20 Yale J.L. & Tech. 234, 237 (2018).
See, e.g., Victoria Hudgins, Casetext Launches New Brief-Writing Automation Platform Compose, Legaltech News (Feb. 25, 2020, 5:00 AM), https://www.law.com/legaltechnews/2020/02/25/casetext-launches-new-brief-writing-automation-platform-compose/ [https://perma.cc/V7YK-VUXV]. AI’s memo writing capabilities are discussed in Part 3 of this Article, in the section “AI approach to Step 10: Writing the office memorandum.”
Legal writing teachers may slightly vary these steps; what is laid out here offers a basic template for the skills involved.
Obviously this activity can occur in a number of ways: for example, a client interview or an assignment from a senior attorney. Here we are simplifying and imagining that the facts come directly from a client.
Steinberg v. Petta, 501 N.E.2d 1263 (Ill. 1986); Beggs v. Griffith, 913 N.E.2d 1230 (Ill. App. Ct. 2009); Van Plew v. Riccio, 739 N.E.2d 1023 (Ill. App. Ct. 2000); Docherty. Sadler, 689 N.E.2d 332 (Ill. App. Ct. 1997); Severson v. Ring, 615 N.E.2d 1 (Ill. App. Ct. 1993). A good researcher might also find an out-of-state case that deals with the issue of involuntary care since JC’s lack of voluntariness in caring for the dog on this occasion could be important. Here, Rodriguez v. Cordasco, 652 A.2d 1250 (N.J. Super. Ct. App. Div. 1995).
See generally Marc Queudot, Eric Charton & Marie-Jean Meurs, Improving Access to Justice with Legal Chatbots, 3 Stats 356 (2020), https://doi.org/10.3390/stats3030023 [https://perma.cc/55FN-4YQD].
Dong Yu & Li Deng, Automatic Speech Recognition: A Deep Learning Approach 307 (2015) (“ASR [Automated Speech Recognition] systems still perform poorly . . . even given the recent technology advancements . . . with spontaneous speech in which the speech is not fluent, with variable speed or with emotions.”).
Armin Seyeditabari, Narges Tabari & Wlodek Zadrozny, Emotion Detection in Text: A Review, arXiv (June 2, 2018), https://arxiv.org/pdf/1806.00674.pdf [https://perma.cc/DKV3-3VF7]. See also Ashrita R. Murthy & K. M. Anil Kumar, A Review of Different Approaches for Detecting Emotion from Text, IOP Conference Series: Materials Science & Engineering, 1110 012009 (2021), https://iopscience.iop.org/article/10.1088/1757-899X/1110/1/012009 [https://perma.cc/3U9G-PND7] (last visited Apr. 30, 2022).
Johannes Dimyadi, Sam Bookman, David Harvey & Robert Amor, Maintainable Process Model Driven Online Legal Expert Systems, 27 Artificial Intelligence & L. 93, 93 (2019).
Services such as Neota Logic and A2J Author can assist in creating the expert systems and authoring the rules. See Neota, https://www.neotalogic.com/ [https://perma.cc/GK2V-EYRB] (last visited Apr. 30, 2022); A2J Author, https://www.a2jauthor.org/ [https://perma.cc/AQ87-UNGZ] (last visited Apr. 30, 2022). Law school clinics employ online expert systems to screen potential clients and record information about their legal problems. See Roger V. Skalbeck, Tech Innovation in the Academy, in AALL & ILTA Digital White Paper: The New Librarian 74, 77 (2012), http://epubs.iltanet.org/i/87421-the-new-librarian/72?m4= [https://perma.cc/6ZEP-8WZW]; see also Ronald W. Staudt & Andrew P. Medeiros, Access to Justice and Technology Clinics: A 4% Solution, 88 Chi.-Kent L. Rev. 695, 716 (2012) (advising that “new attorneys will need to be familiar with the processes involved in building legal expert systems”). Neota Logic features examples of web-based expert systems that guide clients to appropriate law firm resources or personnel for various types of claims. See https://demo-portal.neotalogic.com/a/home [https://perma.cc/N7SV-BEWC] (last visited Apr. 30, 2022).
On the research challenges of extracting rules from statutory texts, see Ashley, supra note 5, at 259–84 (Chapter 9 entitled “Extracting Information from Statutory and Regulatory Texts”).
Vanessa Mai, Caterina Neef & Anja Richert, "Clicking vs. Writing"—The Impact of a Chatbot’s Interaction Method on the Working Alliance in AI-based Coaching, Coaching | Theorie & Praxis § 5.2 (Jan. 14, 2022), https://link.springer.com/article/10.1365/s40896-021-00063-3 [https://perma.cc/M7SJ-CNW8].
See Richard Zorza, The Access to Justice “Sorting Hat”: Towards a System of Triage and Intake that Maximizes Access and Outcomes, 89 Denv. U. L. Rev. 859, 878–79 (2011) (describing how technology could assist in obtaining information from a client).
Depending on the answers, the expert system would pursue particular claims. For instance, in the early 1980s, an expert system on product liability posed questions and provided answer options like these:
Was the victim either the user or purchaser of the product? (Yes / No)
What was the status of the product when it was sold by the defendant? (Defective / Non-defective)
Was the product modified after manufacture by parties other than the defendant? (Yes / No)
Was the nature of the use of the product foreseeable? (Yes / No)
What is the legal status of the victim? (Adult / Minor)
Did the victim know the product was defective before he used it? (Yes / No)
Did the victim continue using the product, even after he found it defective? (Yes / No)
Did the victim have a means for protecting himself from the dangers of using the product? (Yes / No)
Did the victim use this means to protect himself? (Yes / No)
Did the victim know and appreciate the danger involved in the use of the product? (Yes / No)
What were the medical expenses of the plaintiff? $6,000
Donald A. Waterman & Mark A. Peterson, Models of Legal Decisionmaking: Research Design and Methods 45–46 (1981), https://www.rand.org/pubs/reports/R2717.html [https://perma.cc/9QF7-TDJL]. One can readily imagine expanding the questions with branches to cover related claims for negligence, causing injury to a third party, or injury to property or pain and suffering.
For a recent example of an online expert system that allows a user to navigate through complex legal options involving international family law, see Dimyadi et al., supra note 18, at 107–09.
The expert system in Waterman & Peterson, supra note 23, at 16, had rules to determine which of four states’ product liability law applied. Similarly, a triage component of the expert system in Dimyadi et al., supra note 18, at 107–09 had rules to resolve which international family law conventions applied.
Callister, supra note 1, at 187.
Id. at 170, 172, 195. Casetext, https://casetext.com/v2/ [https://perma.cc/W6RR-M85L] (last visited May 23, 2022).
Our attempts to conduct a similar search with With Lexis+ failed. On May 24, 2022, we cut and pasted the hypothetical of Figure 1 into the search box of Lexis+, having selected Illinois as the jurisdiction. The program retrieved no cases or statutes. Presumably, the input was too long.
Soha Khazaeli, Janardhana Punuru, Chad Morris, Sanjay Sharma, Bert Staub, Michael Cole, Sunny Chiu-Webster & Dhruv Sakalley, A Free Format Legal Question Answering System, in Proceedings of the Natural Legal Language Processing Workshop 107, 108–10 (2021).
Thomson Reuters Enterprise Centre GmbH v. ROSS Intelligence Inc., 529 F. Supp. 3d 303 (D. Del. 2021). See Press Release, ROSS Intelligence, ROSS Intelligence Says Allegations of Copyright Theft Are False, Motivated by Fear of Competition (May 7, 2020), https://blog.rossintelligence.com/post/westlaw-copyright-allegations-are-false [https://perma.cc/H3QF-UGXH]. As of February 7, 2022, the litigation is still dealing with document discovery and motions to dismiss claims. See Julie Sobowale, Digging In: The ROSS Antitrust Saga Against Westlaw Continues, CBA/ABC National (Feb. 7, 2022), https://www.nationalmagazine.ca/en-ca/articles/legal-market/legal-tech/2022/digging-in [https://perma.cc/SL7X-KHAG].
Remus & Levy, supra note 9, at 503. Thomson Reuters offers a legal question answering service connected with Westlaw Edge called WestSearch Plus. Lexis Nexis offers Lexis Answers. See infra notes 66–67 and accompanying text.
ROSS Intelligence, supra note 8; see also Remus & Levy, supra note 9, at 503.
See Remus & Levy, supra note 9, at 503 & n.4.
Profile of ROSS Intelligence, Forbes, https://www.forbes.com/profile/ross-intelligence/?sh=10ed81c71e85 [https://perma.cc/32ZE-2SFUf] (last visited Apr. 30, 2022).
See Remus & Levy, supra note 9, at 523.
Id.
Ruben Kruiper, Ioannis Konstas, Alasdair Gray, Farhad Sadeghineko, Richard Watson & Bimal Kumar, SPaR.txt, A Cheap Shallow Parsing Approach for Regulatory Texts, arXiv (Oct. 4, 2021), https://arxiv.org/pdf/2110.01295.pdf [https://perma.cc/Q8SS-TPW4].
Stanford Parser, http://nlp.stanford.edu:8080/parser/index.jsp [https://perma.cc/YBN6-MAJE] (last visited Apr. 30, 2022).
Jaromir Savelka, Vern R. Walker, Matthias Grabmair & Kevin D. Ashley, Sentence Boundary Detection in Adjudicatory Decisions in the United States, 58 Traitement Automatique des Langues, no. 2, at 21, 22 (2017).
See, e.g., Alan Buabuchachart, Katherine Metcalf, Nina Charness & Leora Morgenstern, Classification of Regulatory Paragraphs by Discourse Structure, Reference Structure, and Regulation Type, in 259 Frontiers in Artificial Intelligence and Applications: Legal Knowledge and Information Systems, 59, 59–62 (Kevin D. Ashley ed., 2013).
See generally Ashley, supra note 3, at 259–84 (Chapter 9 entitled “Extracting Information from Statutory and Regulatory Texts”).
Jiansong Zhang & Nora M. El-Gohary, Automated Information Transformation for Automated Regulatory Compliance Checking in Construction, 29 J. Computing in Civ. Eng’g, no. 4 (2015); Travis D. Breaux & David G. Gordon, Regulatory Requirements as Open Systems: Structures, Patterns and Metrics for the Design of Formal Requirements Specifications, Carnegie Mellon University Technical Report CMU-ISR-11-100 (2011); Travis D. Breaux & David G. Gordon, Regulatory Requirements Traceability and Analysis Using Semi-Formal Specifications, in International Working Conference on Requirements Engineering: Foundation for Software Quality, RESFQ 2013: Requirements Engineering: Foundation for Software Equality 141, 157 (2013).
See, e.g., Kenji Takano, Makoto Nakamura, Yoshiko Oyama & Akira Shimazu, Semantic Analysis of Paragraphs Consisting of Multiple Sentences Towards Development of a Logical Formulation System, 223 Frontiers in Artificial Intelligence and Applications: Legal Knowledge and Information Systems 117, 119–20 (2010); Ngo Xuan Bach, Nguyen Le Minh, Tran Thi Oanh & Akira Shimazu, A Two-Phase Framework for Learning Logical Structures of Paragraphs in Legal Articles, 12 ACM Transactions on Asian Language Info. Processing (TALIP), no. 1, article 3, 2–3 (2013).
See Zhang & El-Gohary, supra note 42.
Layman E. Allen & C. Rudy Engholm, Normalized Legal Drafting and the Query Method, 29 J. Legal Educ. 380, 402–04 (1977); Layman E. Allen & Charles S. Saxon, Some Problems in Designing Expert Systems to Aid Legal Reasoning, in Proceedings of the First International Conference on Artificial Intelligence & Law 94 (1987); see also Ashley, supra note 3, at 40–44.
Current efforts to develop “computable” statutes need to resolve syntactic ambiguities inherent in statutory texts. See, e.g., Tom Barraclough, Hamish Fraser & Curtis Barnes, Legislation as Code for New Zealand (Mar. 2021), http://www.nzlii.org/nz/journals/NZLFRRp/2021/3.html [https://perma.cc/7BCP-DYAP].
See, e.g., Dimyadi et al., supra note 18, at 116.
Lexis Answers on Lexis+, http://lexisnexis.custhelp.com/app/answers/answer_view/a_id/1098212/~/lexis-answers-on-lexis-advance [https://perma.cc/FH2K-9E2Q] (last visited Apr. 30, 2022); Callister, supra note 1, at 200.
Lexis Answers on Lexis+, supra note 48.
NLP-progress, http://nlpprogress.com/english/natural_language_inference.html [https://perma.cc/YPU7-R4UN] (last visited Apr. 30, 2022).
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy & Samuel R. Bowman, GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding, arXiv (Feb. 22, 2019), https://arxiv.org/pdf/1804.07461.pdf [https://perma.cc/HXG7-6G4U].
Mi-Young Kim & Randy Goebel, Two-Step Cascaded Textual Entailment for Legal Bar Exam Question Answering, in Proceedings of the 16th edition of the International Conference on Artificial Intelligence & Law 283, 283–84 (2017); see also Mi-Young Kim, Juliano Rabelo & Randy Goebel, Statute Law Information Retrieval and Entailment, in Proceedings of the Seventeenth International Conference on Artificial Intelligence & Law 283, 283–84 (2019). One sample question asks, “Is it true that a special provision that releases warranty can be made, but in that situation, when there are rights that the seller establishes on his/her own for a third party, the seller is not released of warranty?” Kim & Goebel, supra, at 283. Another sample question states, “In cases an agent is entrusted to perform any specific juristic act, if the agent performs such act in accordance with the instructions of the principal, the principal may not assert that the agent did not know a particular circumstance without negligence which the principal did not know due to his/her negligence.” Kim, Rabelo & Goebel, supra, at 287.
Kim & Goebel, supra note 52, at 285–88; Kim, Rabelo & Goebel, supra note 52, at 285–86.
Anne Gardner, An Artificial Intelligence Approach to Legal Reasoning 160–67 (1987). As elaborated in Edwina Rissland, Artificial Intelligence and Law: Stepping Stones to a Model of Legal Reasoning, 99 Yale L.J. 1957, 1969 (1990), Gardner developed heuristics for deciding whether, given a fact situation, the applicability of term in a legal rule presented a hard or easy question of law. These heuristics depended on whether the term had an applicable commonsense definition and whether there were relevant examples or counterexamples of the term’s application. Id. at 1970. The method was heuristic in that it was not guaranteed to work, but it often did work. Id. at 1966. The approach was elegant because it was not computationally as expensive as always attempting to generate arguments regarding all potentially applicable terms in a legal rule. Id. at 1970.
An important exception is Thorne McCarty’s classic work on TaxmanII. L Thorne McCarty & Natesa Sridharan, The Representation of an Evolving System of Legal Concepts: II. Prototypes and Deformations, in 1 Proceedings of the 7th International Joint Conference on Artificial Intelligence 246 (1981). It employed a logical representation of the meaning of a small set of legal concepts involving corporate tax and employed prototypes and deformations to identify case-based and example-based arguments about their meaning, but it was limited in its scope and realization to modeling one U.S. Supreme Court case. L. Thorne McCarty, An Implementation of Eisner v. Macomber, in Proceedings of the 5th International Conference on Artificial Intelligence and Law 276, 277-79 (1995). Its analysis began with a manually inputted representation of cases or hypotheticals based on a human’s reading of the text; the program did not analyze the texts itself.
See, e.g., Karl Branting, Building Explanations from Rules and Structured Cases, 34 Int’l J. Man-Machine Stud. 797 (1991); Kevin Ashley & Stefanie Brüninghaus, Computer Models for Legal Prediction, 46 Jurimetrics J. 309 (2006); Edwina Rissland & David Skalak, CABARET: Statutory Interpretation in a Hybrid Architecture, 34 Int’l J. Man-Machine Stud. 839 (1991); Matthias Grabmair & Kevin Ashley, Facilitating Case Comparison Using Value Judgments and Intermediate Legal Concepts, in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Law 161 (2011).
Id.
Branting, supra note 56.
Kevin D. Ashley, Reasoning with Cases and Hypotheticals in HYPO, 34 Int’l J. Man-Machine Stud. 753, 757, 761 (1991).
Vincent Aleven, Using Background Knowledge in Case-Based Legal Reasoning: A Computational Model and an Intelligent Learning Environment, 150 Artificial Intelligence 183 (2003).
Rissland & Skalak, supra note 56.
Ashley & Brüninghaus, supra note 56.
Grabmair & Ashley, supra note 56.
Branting, supra note 56 at 800.
Susan Nevelow Mart, et al., Inside the Black Box of Search Algorithms, AALL Spectrum, Nov.-Dec. 2019, at 10, https://scholar.law.colorado.edu/articles/1238/ [https://perma.cc/2DHX-E6Y5] (last visited Apr. 30, 2022).
Tonya Custis, et al., Westlaw Edge AI Features Demo: KeyCite Overruling Risk, Litigation Analytics, and WestSearch Plus, in Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law 256 (2019). Mart et al., supra note 66, at 14.
Two AI and Law projects came close to this goal; both modeled legal argument as theory construction. Thorne McCarty’s program aimed at constructing competing rule-like theories induced from two decided cases and one agreed-upon hypothetical justifying an argued-for outcome in one new case. See McCarty & Sridharan, supra note 55. Chorley’s and Bench-Capon’s AGATHA program induced rules embodying preferences among competing factors and values and used them to construct theory-based arguments on how to resolve a new case. Alison Chorley & Trevor Bench-Capon, AGATHA: Using Heuristic Search to Automate the Construction of Case Law Theories, 13 Artificial Intelligence & L. 9 (2005); Alison Chorley & Trevor Bench-Capon, An Empirical Investigation of Reasoning with Legal Cases Through Theory Construction and Application, 13 Artificial Intelligence & L. 323 (2005).
An account of a systematic effort to identify factors in landlord-tenant decisions and of the challenges of extracting them automatically may be found in Hannes Westermann, Vern R. Walker, Kevin D. Ashley & Karim Benyekhlef, Using Factors to Predict and Analyze Landlord-Tenant Decisions to Increase Access to Justice, in Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law 133 (2019).
Karl Branting, Craig Pfeifer, Bradford Brown, Lisa Ferro, John Aberdeen, Brandy Weiss, Mark Pfaff & Bill Liao, Scalable and Explainable Legal Prediction, 29 Artificial Intelligence & L. 213 (2021).
Id. at 232–35. WIPO’s Arbitration and Mediation Center provides rules and mechanisms to resolve internet domain name disputes, without the need for litigation in court. https://www.wipo.int/amc/en/center/index.html [https://perma.cc/C9FG-S6RZ] (last visited May 22, 2022).
Id.
Mohammad H. Falakmasir & Kevin D. Ashley, Utilizing Vector Space Models for Identifying Legal Factors from Text, in 302 Frontiers in Artificial Intelligence and Applications: Legal Knowledge and Information Systems 183 (Adam Wyner & Giovanni Casini eds., 2017).
For a detailed account of how this might be accomplished, see Ashley, supra note 3, at 350–92 (Chapter 12 entitled “Cognitive Computing Legal Apps”).
Grabmair & Ashley, supra note 56.
Id.
See, e.g., Nikolaos Aletras, Dimitrios Tsarapatsanis, Daniel Preoţiuc-Pietro & Vasileios Lampos, Predicting Judicial Decisions of the European Court of Human Rights: A Natural Language Processing Perspective, 2 PeerJ Computer Science e93 (2016). Masha Medvedeva, Michel Vols & Martijn Wieling, Using Machine Learning to Predict Decisions of the European Court of Human Rights, 28 Artificial Intelligence & L. 237 (2020).
See Heung-Il Suk, An Introduction to Neural Networks and Deep Learning, in Deep Learning for Medical Image Analysis 3 (2017).
Ilias Chalkidis, Ion Androutsopoulos & Nikolaos Aletras. Neural Legal Judgment Prediction in English, arXiv (June 5, 2019), https://arxiv.org/pdf/1906.02059.pdf [https://perma.cc/8FY6-AQVY].
Id.
Zhou, supra note 5 at 4.
Id.
For a brief description of neural networks, see Suk, supra note 76.
Chalkidis et al., supra note 78.
Heet Sankesara, Hierarchical Attention Networks, Analytics Vihya (Aug. 23, 2018), https://medium.com/analytics-vidhya/hierarchical-attention-networks-d220318cf87e [https://perma.cc/TKS8-SRX5].
Id.
Chalkidis et al., supra note 78.
Karl Branting, Brandy Weiss, Bradford Brown, Craig Pfeifer, A. Chakraborty, Lisa Ferro, Mark Pfaff & Alexander Yeh, Semi-Supervised Methods for Explainable Legal Prediction, in Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law 22 (2019).
Branting et al., supra note 69.
Branting et al., supra note 87.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei & Ilya Sutskever, Language Models Are Unsupervised Multitask Learners (2019), https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf [https://perma.cc/U5KU-2YV7].
John Pavlus, Machines Beat Humans on a Reading Test. But Do They Understand?, Quanta Magazine (Oct. 17, 2019), https://www.quantamagazine.org/machines-beat-humans-on-a-reading-test-but-do-they-understand-20191017/ [https://perma.cc/YFW2-DEKU].
Id.
Id.
Id.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al., Language Models Are Few-Shot Learners, arXiv (July 22, 2020), https://arxiv.org/pdf/2005.14165.pdf [https://perma.cc/T4ND-5QG7].
Id.
Pavlus, supra note 91.
Brown et al., supra note 95.
Id.
Radford et al., supra note 90.
Talk to Transformer, https://talktotransformer.com/ (now called InferKit, https://inferkit.com/) [https://perma.cc/XE4H-Z5GB] (last visited Apr. 30, 2022). See Kelsey Piper, An AI Helped Us Write This Article, Vox (Feb. 14, 2019, 12:50 PM), https://www.vox.com/future-perfect/2019/2/14/18222270/artificial-intelligence-open-ai-natural-language-processing [https://perma.cc/F9AT-LBMW].
As illustrated in Figure 9, GPT-2 and its successor, GPT-3 often leave sentences unfinished. See, e.g., Miguel Grinberg, The Ultimate Guide to OpenAI’s GPT-3 Language Model, https://www.twilio.com/blog/ultimate-guide-openai-gpt-3-language-model [https://perma.cc/CM32-D9XC] (last visited May 22, 2022).
See, e.g., Illinois Pattern Jury Instructions-Civil § 30.04.01 Measure of Damages—Disability/Loss of a Normal Life (citing Smith v. City of Evanston, 631 N.E.2d 1269 (Ill. App. Ct. 1994) (“Loss of a normal life is recognized as a separate element of compensable damages in Illinois.”).
Dog Bites, Brabender Law LLC, https://bc-firm.com/chicago-dog-bite-lawyer/ [https://perma.cc/8P3P-UGT2] (last visited Apr. 30, 2022). The term is also used on the website of Law Offices of John J. Malm & Associates. Illinois Dog Bite Injuries, Law Offices of John J. Malm & Associates, https://www.malmlegal.com/illinois-dog-bite-injuries.html [https://perma.cc/M6ZC-EYLZ] (last visited Apr. 30, 2022). While a Google search did not find a Jason A. Bendoff, an attorney named Bendoff is mentioned on the Malm & Associates website.
Tony Zhao, Eric Wallace, Shi Feng, Dan Klein & Sameer Singh, Calibrate Before Use: Improving Few-Shot Performance of Language Models, arXiv (June 10, 2021), https://arxiv.org/pdf/2102.09690.pdf [https://perma.cc/PV77-77ZR].
Casetext, https://casetext.com/v2/ [https://perma.cc/W6RR-M85L] (last visited May 24, 2022).
Westlaw Edge Quick Check, https://1.next.westlaw.com/QuickCheck?transitionType=Default&contextData=(sc.Default) (last visited May 24, 2022).
Lexis+ Brief Analysis
https://plus.lexis.com/briefAnalysis?crid=82c5aa19-6510-49f2-9aec-cc1ffad70cad#/briefAnalysis/singleBrief (last visited May 24, 2022). Fastcase Cloud Linking
In an uploaded brief or memo, Fastcase Cloud Linking augments case citations with publicly available hyperlinks to the cited cases. It does not appear to analyze the text, however. Fastcase Cloud Linking, https://fc7.fastcase.com/ (last visited May 24, 2022).
Hudgins, supra note 11.
For example, LEGAL-BERT is a language model pre-trained on a corpus including legal documents. It improved performance on a number of tasks. Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras & Ion Androutsopoulos, LEGAL-BERT: The Muppets Straight Out of Law School, arXiv (Oct. 6, 2020), https://arxiv.org/pdf/2010.02559.pdf [https://perma.cc/UD9W-X29V].
Lazar Peric, Stefan Mijic, Dominik Stammbach & Elliott Ash, Legal Language Modeling with Transformers, Proceedings of ASAIL (2020), http://ceur-ws.org/Vol-2764/paper2.pdf [https://perma.cc/89DP-FSAZ].
Karen Hao, AI Still Doesn’t Have the Common Sense to Understand Human Language, MIT Tech. Rev. (Jan. 31, 2020), https://www.technologyreview.com/s/615126/ai-common-sense-reads-human-language-ai2/ [https://perma.cc/H9Q4-ZD8Q].
Peric et al., supra note 111, at 6, 8.
According to David Ferrucci, the leader of IBM’s team that developed Watson, transformer models like GPT-3 are “super-parrots.” “They do well at narrow tasks, but only by constantly asking themselves one simple question: ‘Based on all the documents I’ve seen, what would a human likely say here?’ . . . What’s left unwritten . . . is the vast body of shared experience that led humans to write the words in the first place.” David Ferrucci, Can Super-Parrots Ever Achieve Language Understanding?, Elemental Cognition (May 21, 2020),
https://medium.com/@ElementalCognition/can-super-parrots-ever-achieve-language-understanding-8307dfd3e87c [https://perma.cc/C64D-S6E7]. Presumably, much of the common sense shared experience of legal practice is also unwritten and inaccessible to transformer models. GPT-3 can generate realistic appearing answers with little training, but one cannot yet rely on their legal correctness.
Gary Marcus & Ernest Davis, Rebooting AI: Building Artificial Intelligence We Can Trust (2019), adapted in Gary Marcus & Ernest Davis, If Computers Are So Smart, How Come They Can’t Read?, Wired. (Sep. 10, 2019), https://www.wired.com/story/adaptation-if-computers-are-so-smart-how-come-they-cant-read/ [https://perma.cc/9MH3-N56P].
See Jeremy Paul, Changing the Subject: Cognitive Theory and the Teaching of Law, 67 Brook. L. Rev. 987, 1006, 1008, 1022 (2002).
Supra Part 2.
Jaromir Savelka, Matthias Grabmair & Kevin D. Ashley, A Law School Course in Applied Legal Analytics and AI, 37 Law in Context 134 (2020).
The excerpts are from Teresa Kissane Brostoff & Ann Sinsheimer, United States Legal Language and Culture: An Introduction to the U.S. Common Law System (3d ed. 2013).